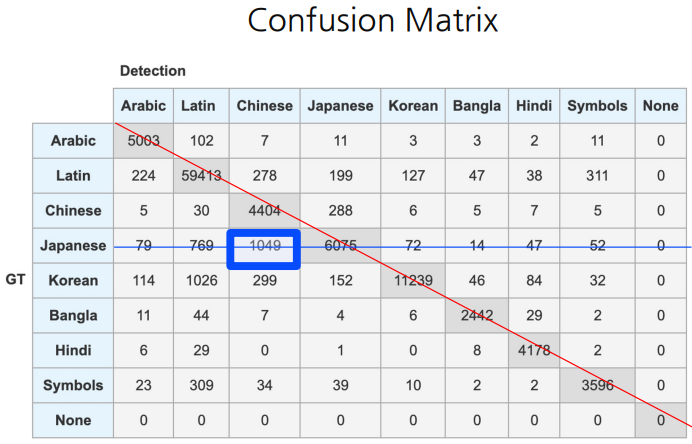
[OCR] 글자 검출 모델 평가 방법(DetEval)
성능평가 = 새로운 데이터가 들어왔을 때 얼마나 잘 작동하는가? (일반화 성능)
이를 위해
Train - Test Split
Train - Validation Split
K-fold Cross Validation
방법등을 이용한다

또한 아래와 같은 추가 분석을 하여서 더 좋은 성능을 이끌어낸다
ConfusionMatrix
Recall / Precision

Precision Vs Recall
Precision : 예측이 Positive 일때 실제로 True인 경우 (예측 기반)
- True인 것을 전부 찾아내지를 못한다.
Recall : 실제 True 일때 예측도 Positive 인 경우 (실제 기반)
- True가 아닌 것을 True라고 할 수 있다.
OCR에서는 어떻게 평가를 할까?
1. 테스트 이미지에 대해 결과값(좌표값)을 뽑느다
2. 예측 결과와 정답을 매칭한다
3. 예측과 정답사이의 유사도를 하나의 수치로 뽑는다
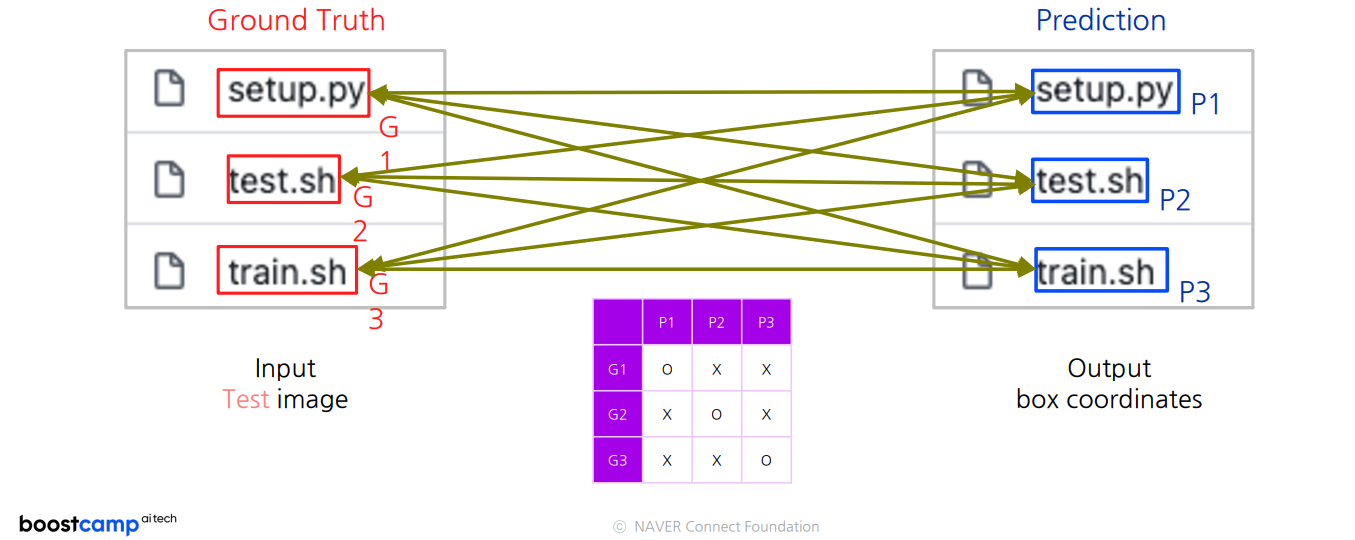
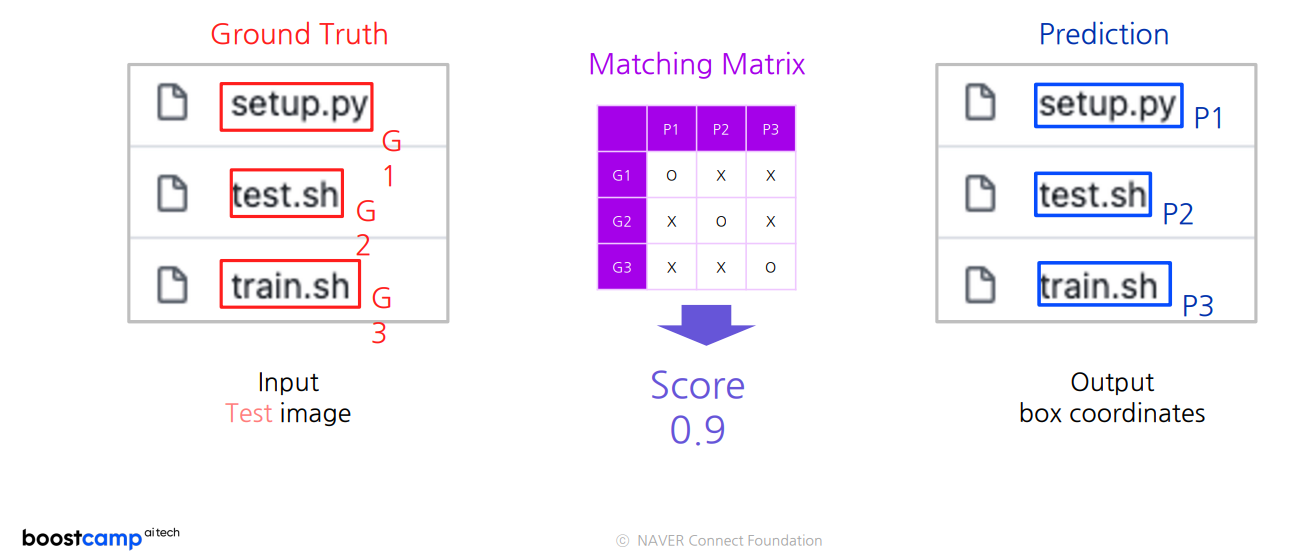
이러기 위해서는 다음 두개의 방법이 정의되어야 한다
두 영역 간의 매칭 판단 방법(매칭 행렬 계산법)
매칭 행렬에서 유사도 수치 계사 방법 (유사도 계산법)
매칭 행렬 계산법 : Ground Truth와 Prediction이 얼마나 겹칠 때 매칭되었다고 볼 것 인지
유사도 계산법 : 만약 매칭이 되었다고 판단이 되면 이 둘의 유사도를 어떻게 정의할 것 인지
매칭 행렬 계산법
1. IOU (Intersection of Union)
IOU = Area(P ∩ G) / Area(P ∪ G) -> P : prediction , G : ground truth

2. Area Recall & Area Precision

Area Precision = 정답과 예측박스가 겹치는 영역 / 예측 박스의 영역
Area Recall = 정답과 예측박스가 겹치는 영역 / 정답 박스의 영역
앞서 말했듯이 Precision은 예측(Predict) 기반 이므로 예측박스가 아래로
Recall은 실제(Ground Truth) 기반이므로 정답박스가 아래로
둘다 공통적으로 겹치는 부분이 위로
유사도 계산법
Matching 행렬에서 유사도 수치 1개를 뽑는 Scoring 과정
One-to-One | One-to-Many | Many-to-One
위의 세가지 경우에 따라 Score를 매긴다
1. One - to - One Matching
정답에 해당하는 영역 1개가 예측에 해당되는 영역들 중 하나에 매칭
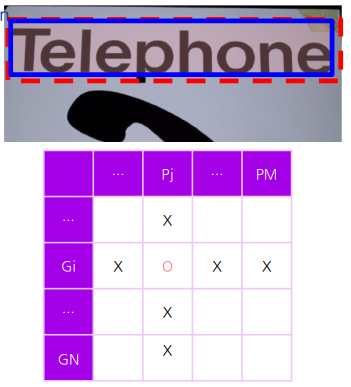
2. One - to - Many Matching (Split)
정답영역 하나에 여러 예측영역 매칭
(하나의 정답영역이 여러개로 쪼개져 예측)
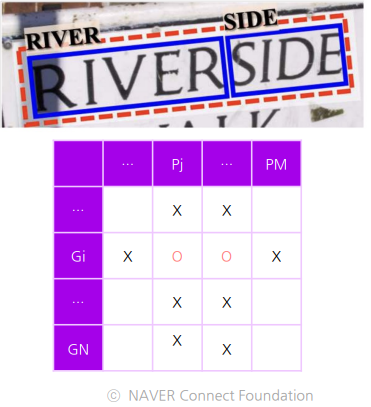
3. Many - to - One Matching (Merge)
정답영역 여러개를 포함하는 하나의 예측영역이 존재

DetEval
13년 ICDAR에서 사용

1. Matching Matrics 채우기

모든 정답영역과, 예측영역 간의 매칭 정도를 area recall 과 area precision을 전부 계산한다
(관계 하나 마다 두개의 값을 모두 구함)
2. Area recall 과 Area precision을 모든 관계에 대해 구한다

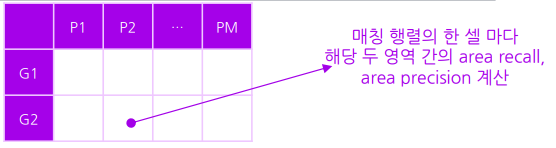
각 셀마다 두 영역간의 area recall 과 area precision을 계산하므로
내 생각 대로라면 저 표 하나에 두개의 값이 들어간다
3. Matching Matrics의 값을 Binary[0,1] 하게 바꿔줌 (Area recall / Area Precision)


4. Binary Matrics를 보면서 one-to-one / one-to-many / many-to-one 관계를 파악하여 score매김

결과 값 : 0 , 0.8 , 1
0.8 ?? : One-to-Many는 split의 경우로 이를 지양하기위해 penalty를 부여한다
Example

5. Score Matrics를 보면서 Precision과 Recall을 계산
Precision : 예측 영역 기준으로 평균 값
Recall : 정답 영역 기준으로 평균 값
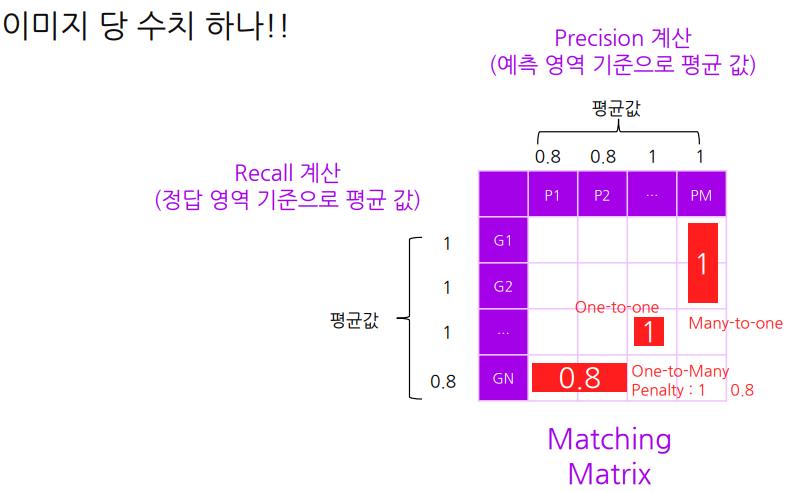
예시의 경우
Precision : (0.8 + 0.8 + 1 + 1) / 4
Recall : (1 + 1 + 1 + 0.8) / 4
6. 최종 Score를 (조화평균을 이용하여서 계산)

Reference
Wolf,C.,&Jolion,J.M.(2006).Objectcount/areagraphsfortheevaluationofobjectdetectionandsegmentationalgorithms. (IJDAR), 8(4),280-296.