Decision Tree, Random Forest, ExtraTressClassifier
1. Decision Tree (결정트리)
흔히 의사결정나무라고 한다
분류와 회귀 모두 가능한 지도 학습 모델 중에 하나이다
쉽게 스무고개를 한다고 생각하면 된다
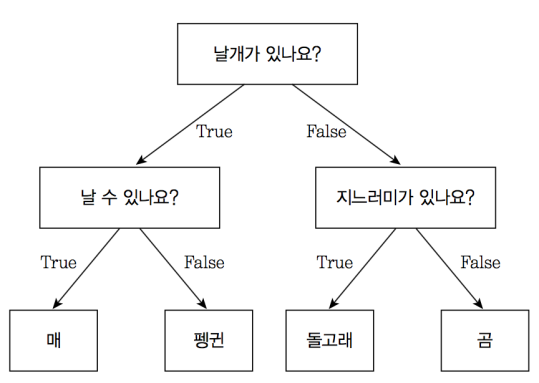
한번의 분기마다 T/F 두개로 분기한다
여기서 질문을 담은 것이 Node라고 하고 첫 질문을 Root Node 맨 마지막 노드를 Terminal Node 혹은 Leaf Node라고 한다
이를 통해서 어떻게 나누냐

이렇게 데이터를 가장 잘 구분할 수 있는 질문을 기준으로 나누고
이어서 한번더

나눈다.
느낌이 오다 싶히 조금만 깊게 해도 쉽게 오버피팅이 된다

이러한 것을 막기 위해서 Pruning이라는 방법(노드의 분기 개수를 제한 하는 것(최대 깊이 혹은 분기 노드 개수를 지정))
그러면 결정트리는 어떻게 학습을 하냐
불순도(Impurity)를 최소화 하는 방향으로 학습을 진행한다.
이 불순도를 수치적으로 나타낸 것이 엔트로피 이다
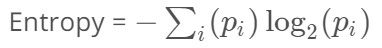
엔트로피 =1 -> 불순도 최대 -> 서로다른 데이터들이 같은 갯수로 한 범주안에 들어가 있다 (골고루 잘 섞였다)
엔트로피 = 0 -> 불순도 최소 -> 딱 구분을 엄청 잘했다 (한 범주에 한가지 종류의 데이터만 들어가있다)

다음과 같은 예시 에서 grade, bumpiness, speedlimit이 Feature이고 Speed가 label 일 때
어떤을 우선으로 나누야 좋을지를 결정해 주는 것이라고 생각하면 된다
grade 로 하는게 제일 좋았다? 그러면 root node를 grade == steep 이런 식으로 가는 것이다
2. Random Forest
위에서 느꼈겠지만 Decision Tree 기법은 데이터에 너무 과적합 한다
이를 개선하기 위해 앙상블 기법으로 랜덤 포레스트를 고안 했다
결정트리를 한개만 만드는 것이 아닌 여러개의 결정트리를 학습시켜서 앙상블을 노리는 것이다
대표적인 것이 Bagging(배깅) boostrap aggregating방법이다
모델 내부에 부트스트랩 샘플을 만든다
(ex, [‘a’, ‘b’, ‘c’, ‘d’]에서 부트스트랩 샘플을 만든다고 하면 [‘b’, ‘d’, ‘d’, ‘c’] , [‘d’, ‘a’, ‘d’, ‘a’], [‘a’, ‘a’, ‘c’, ‘b’] 등이 생성된다)
이렇게 만든 모든 트리를 기반으로 예측을 수행을 한다.
회귀의 경우 모든 예측을 평균하여 결과를 도출하고, 분류는 soft voting 방식을 응용해 사용한다.

3. Extra Trees
랜덤 포레스트에 좀더 Feature과 샘플링에 무작위성을 부여하는 앙상블 모델이다
랜덤포레스트는 최적의 임계값을 특성으로 선택을 하고 엑스트라는 후보 특성을 기반으로 무작위로 분할 하고 최적치를 선택