[DL Basic] 딥러닝의 기초와 흐름
"딥러닝은 AI의 일부이다"

Artificial Intelligence : 인공지능 - 사람의 지능을 모방
Machine Learning : 머신러닝 - Data-driven approach : 데이터 기반 학습
Deep Learning : 딥러닝 - machine learning의 방법중 Neural Networks를 이용한 방법
Deep Learning = 여러가지 분야로 구성
1. Coding Skills (Python, Pytorch, tensorflow...) : 구현실력
2. Linear Algebra + Probability (선형대수 + 확률과 통계) : 수학적 지식
3. Knowing a lot of recent Papers : 논문을 많이 아는 것
<논문을 읽을 때 KeyPoint 4가지>
1. Data : 어떤 데이터를 사용하였는지
2. Model : Data를 어떻게 바꿔서 학습했는지
3. Loss : model의 평가지표를 어떻게 잡았는지
4. Algorithm : Loss를 최소화 하기위해 어떤 방법을 사용했는지
CV의 종류 (대충)
- Classification : 개냐 고양이냐!
- Semantic Segmentation : 한 이미지에 어디가 하늘이고 땅이고 잔디고 사람이냐
(label을 찾는게 아니라 픽셀별로 분류하는 것)
- Detection : Bounding box를 구현하는 것
- Pose Estimation : 스켈레톤 정보를 뽑아내는 것
- Visual QnA : 이미지 + 문장 - ex) 사진속 사람은 눈 색깔은 "Blue"이다
<Loss>
모델과 데이터가 정해졌을 때 모델을 어떻게 학습할지 (Weight 와 Bias를 어떻게 Update 할지)
-> loss를 줄인다고 해서 우리의 목표에 다가간다는 보장은 없다
Loss function이 정해진건 아니지만 일반적으로 사용하는게 있긴하다
1. Regression (MSE)
$$ MSE = \frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{D}(y_{i}^{(d)}-\hat{y}_{i}^{(d)})^2 $$
2. Classification (Cross-Entropy)
$$ CE = -\frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{D}y_{i}^{(d)}log \hat{y}_{i}^{(d)} $$
3. Probabilistic (MLE)
확률적인 모델을 사용할 때 (출력값이 평균,분산 이런거 일 때)
$$MLE = \frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{D}logN(y_{i}^{(d)} ; \hat{y}_{i}^{(d)}, 1)$$
<Regularization>
- 학습을 잘 안되게 해주는 효과
- 단순히 학습데이터에서만 잘 동작하는게 아니라 실생활 or New data에 적합하게 하기 위함
- Dropout
- Early Stopping
- K-fold validation
- Weight decay
- Batch normalization
- Mix up
- Ensemble
- Bayesian Optimization
<Historical Review>
https://dennybritz.com/posts/deep-learning-ideas-that-stood-the-test-of-time/
Deep Learning ideas that have stood the test of time
Deep Learning is such a fast-moving field and the huge number of research papers and ideas can be overwhelming.
dennybritz.com
2012 : AlexNet
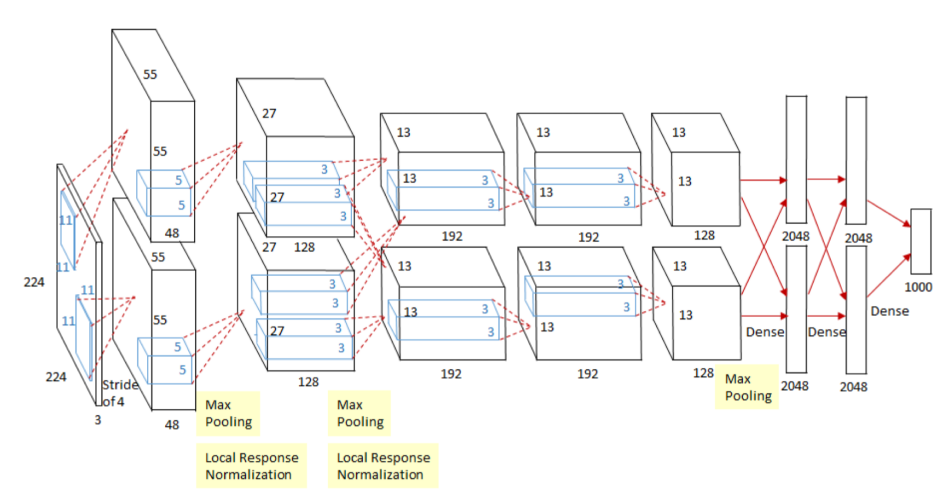
이전에는 ILSVRC 대회에서 커널기반 아니면 SVM등을 사용하다 이거 등장한 이후엔 이것만 씀
224 x 224 이미지를 classification 하는게 목표
2012 : DQN (Deep Q- Network)
강화학습 ex) 알파고

[RL] 강화학습 알고리즘: (1) DQN (Deep Q-Network)
Google DeepMind는 2013년 NIPS, 2015년 Nature 두 번의 논문을 통해 DQN (Deep Q-Network) 알고리즘을 발표했습니다. DQN은 딥러닝과 강화학습을 결합하여 인간 수준의 높은 성능을 달성한 첫번째 알고리즘입니
ai-com.tistory.com
2014 : Encoder / Decoder (NMD)
단어의 연속이 주어질 때 다른 연속된 단어로 뱉어주는 것 (ex) 구글 번역기

2014 : Adam Optimizer
왜 Adam이 SGD 보다 좋을까? 왜 사람들이 Adam을 주로 쓸까??
A: 그냥 좋으니깐 쓰자!! (설명하기 힘듬)

2015 : GAN(Generative Adversarial Network)
ex) 이미지를 스스로 생성 (추후 포스팅 예정)

2017 : Transformer
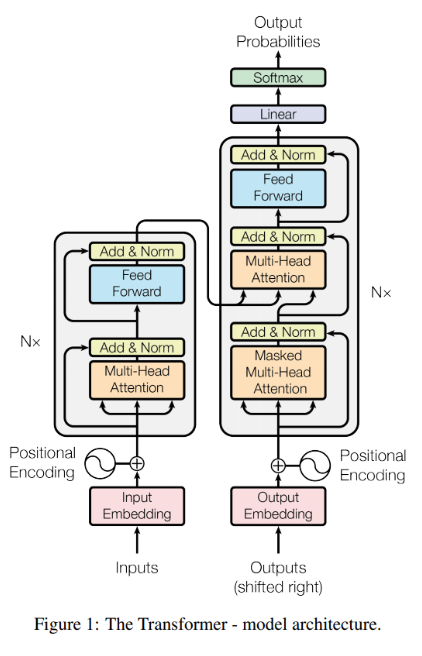
구조를 이해하는 것이 중요 (추후 포스팅 예정)
2018 : BERT(Bidirectional Encoder Representations from Transformers)
(fine-tuned NLP models)
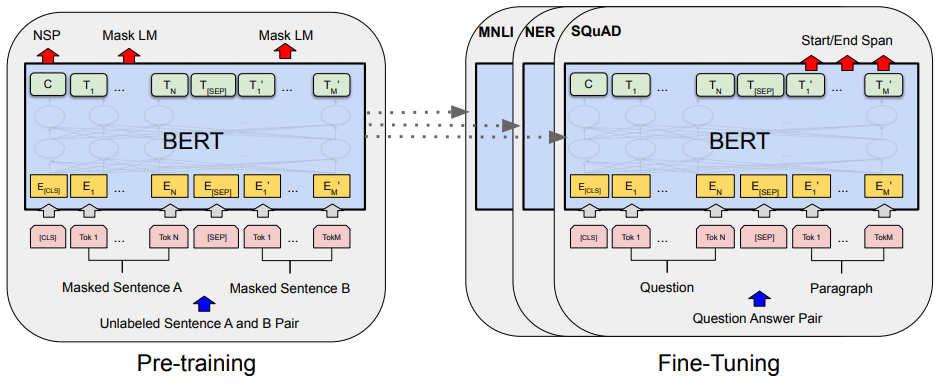
위키피아 등을 활용해 다양한 언어를 Pre-trained + 내가 풀고자 하는 소수의 데이터에 fine tunning
2019 : Big Language Models (GRT-x)
GPT-3 굉장히 큰 Parameter를 가짐
약간의 fine tunning을 통해 문장,표,프로그램 같은 시퀀셜 모델을 만듬
2020 : Self Supervised Learning (SimCLR)

한정된 학습데이터의 한계를 극복하기 위해 라벨을 모르지만 학습에 활용을 함
SimCLR : a simple framework for contrastive learning of visual representations
(이미지를 컴퓨터가 이해할 수 있는 vector로 어떻게 바꿀지)
2020~ : Self Supervised Data Sampling
풀고자 하는 문제를 굉장히 잘 알고 있고 고도화된 도메인이 있을 때 Dataset을 만들어내는 방법
(학습데이터를 만들어서 학습)