[Obj Det] Basic of Object Detection(정의, mAP 등등)
Definition
Classification : 이미지가 무엇인지
Object Detection : 이미지속 객체를 식별 : 이미지 안에 정답이 여러개 있을 수도 있다
(정답이 몇개 있을지도 모름)
자율주행, OCR, 의료분야등등 다양한 Task에서 사용
History

평가방법
성능 : mAP => 얼마나 잘 검출했는지
속도 : FPS, FLOPS => Real time을 요구
< mAP (Mean Average Precision) >
각 클래스당 AP의 평균 (class 별로 AP를 계산한다)

<Topic>
AP(Average Precision)란 무엇일까 : PR- curve의 아랫면적
PR- curve란 무엇일까 : 예측에 대해 Confidence Score을 내립차순으로 정렬한 Recall-precision 그래프
Confidence, Recall, Precision이 무엇일까
Confusion matrix가 무엇일까 => (TP, TN, FP, FN)
아래서 부터 정리해 나가는 것이 좋다
1. Confusion matrix (TP, FN, FP, TN)
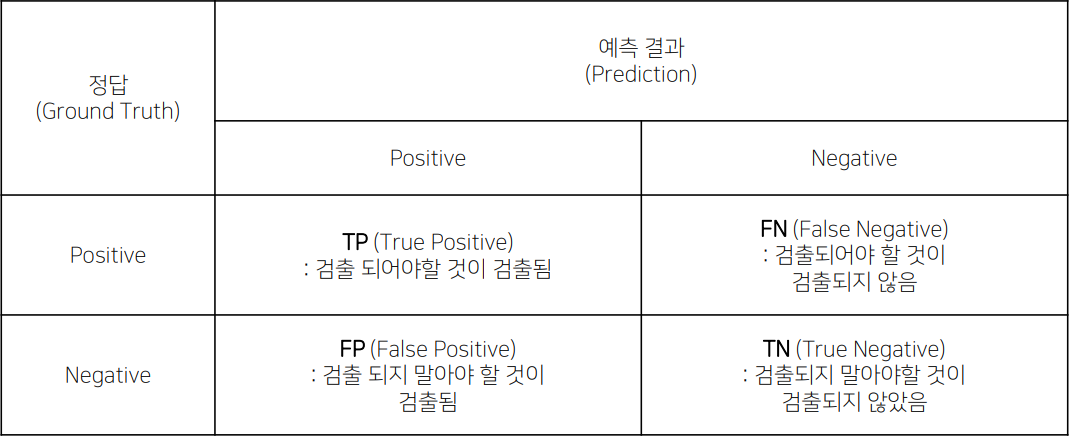
나같은 경우
<모델의 예측>
Positive ,Negative
<실제의 진리>
True, False
=> 이는 Task에 따라 같은 문장도 다르게 해석이 될 수 있다 (목적을 파악하는 것이 중요)
예시 : 범죄자이 아닌데 범죄자라고 판단 (CCTV의 목적: 범죄자 발견)
실제 범죄자 인가 -> 실제의 진리-> False
범죄자라고 판단 -> 모델의 예측 -> Positive
즉 위의 같은 예시는 범죄자 판단 CCTV Task에서 FP이다
2. Precision 과 Recall
- Precision (정밀도) -> 예측 기준
Positive로 분류한 것들(TP,FP) 중에 실제로 Positive한(TP) 비율 (얼마나 정확하게 분류하는지)
(검출하면 진짜임 ㅇㅇ)

=> 함수를 살펴보면 FP을 낮추는 것에 더 힘쓰는 것을 볼 수 있다 (이래서 아래와 같은 한계가 생김)
FP를 낮춘다 => FN 을 높인다 (진리 True, False는 안 바뀌므로)
한계 : 정답인 것을 정답이 아니라고 할 가능성이 높아진다 (Negative을 많이 하게 됨)
- Recall(재현율) = Sensitivity(민감도), TPR(True Positive Rate) -> 정답 기준
정답을 맞춘 애들(TP, FN) 중에 Positive로 판별한(TP) 비율
(진짜를 빠짐 없이 뽑을 거임 ㅇㅇ)

=> 함수를 살펴보면 FN을 낮추는 것에 더 힘쓰는 것을 볼 수 있다(이래서 아래와 같은 한계가 생김)
FN를 낮춘다 => FP을 높인다 (진리 True, False는 안 바뀌므로)
한계 : 정답이 아닌 것을 정답이라고 할 가능성이 높아진다 (Positive을 많이 하게 됨)
- 예시
1.위험한 수술 결정 => Precision을 사용해야 할 것 같음 (검출하면 진짜임 ㅇㅇ)
Precision
심한 질병을 가진 환자들을 모두 찾아내지 못하는 것은 안타깝지만, 병이 없는 사람에게 위험한 수술을 시행하는 것을 방지
Recall
병이 없는 사람한테 위험한 수술을 하는 것이 미안하지만, 심한 질병을 가진 환자들을 모두 치료할 수 있는 것에 목적
2. 아이들 유해 컨텐츠 차단 => Recall을 사용해야 할 것 같음 (진짜를 빠짐 없이 뽑을 거임 ㅇㅇ)
Precision
유해 컨텐츠인것 같은(Positive) 애들을 뽑는 것의 정확도에 힘쓰기
=> 유해 컨텐츠 몇개가 패스가 되는 건 아쉽지만, Positive라 판단하면 거의 진짜 유해 컨텐츠임
Recall
유해 컨텐츠인것을 놓치지 않기
=> 유해 컨텐츠를 빠짐 없이 뽑는 것에 집중 (다 걸러 낼거임, 이러면 유해하지 않은 것도 유해하다고 판단 할 수 있다)
3. 그림 예시

Detect 한 개수 : 8개
실제 라이터 개수 : 5개
정답의 개수 : 4개
Precision : 4/8
Recall : 4/5
3. IOU (Intersection Ober Union)
Ground Truth와 얼마나 겹쳤는지

예측 box와 Ground Truth 박스 영역의 교집합/합집합

<Object Detection에서의 TP , FP>
위의 그림에서 느꼈겠지만 빨강색, 파란색 박스의 기준은 무엇으로 나누었을까?
Classification은 TP와 FP를 구분 짓기가 명확하지만
Object detection은 구분이 명확하지가 않다
이를 위해 도입한 것이 IOU
"즉, Detection은 mAP와 함께 IOU Threshold 를 함께 제시를 해줘야한다"
ex) mAP80 : 우리는 Ground Truth와 80%가 겹쳐야 True라고 해줄거다

만약 Threshold (hyperparameter)가 50이라고 지정을 해줬으면 왼쪽은 FP 오른쪽은 TP이다
(일단 Detection은 했으니 positive임)
4. Confidence Score
검출한 bounding box 내에 해당 class의 객체가 존재할 확률
즉, 특정 바운딩 박스안에 있는 객체가 어떤 물체의 클래스일 확률

다음 그림에서 각 바운딩 박스안에 자동차가 있을 확률
5. PR Curve
=> 예측에 대해 confidence score를 내림차순으로 정렬해서 누적 TP와 FP에 대해 Recall - Precision으로 나타낸 것
예시) 1~10번까지 10개의 예측을 했다고 가정
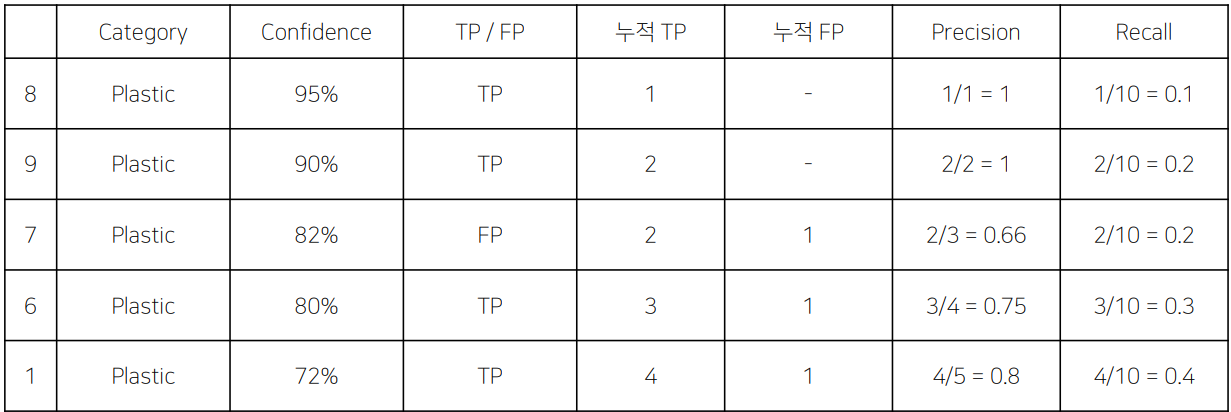
1번의 예시는 72%로 Plastic이라 확신을 하였고 맞았다 (TP)
그동안 누적 TP + FP = 5 , TP = 4, 총 예측 =10
7번의 예시는 82%로 Plastic이라 확신을 하였고 틀렸다 (FP)
이렇게 누적 TP 와 누적 FP에 대해 Precision과 Recall을 구하고
Cofidence에 따라 내림차순으로 정렬한 다음 그래프로 그리면
PR-Curve가 된다
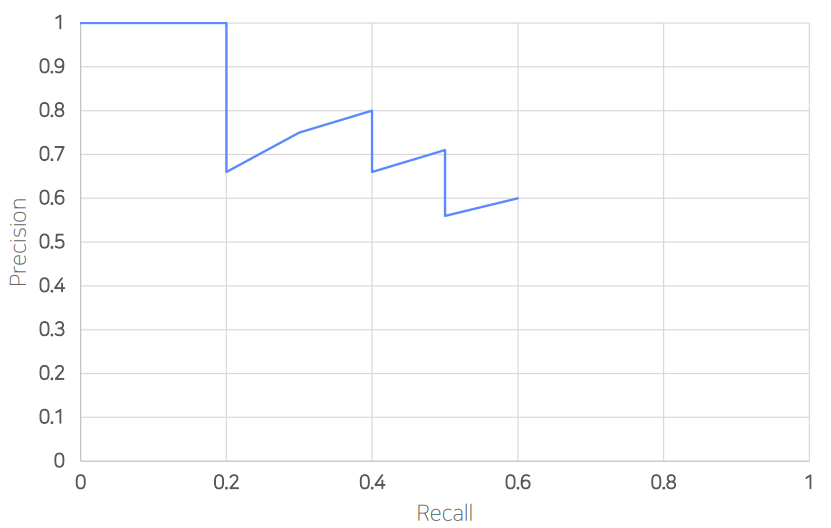
6. AP (Average Precision)
PR Curve의 아랫 면적
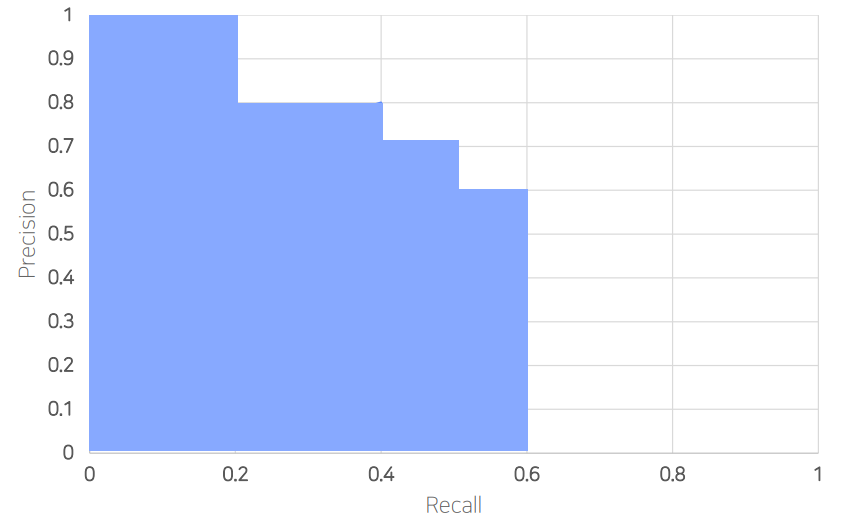
위의 그래프는 "Plastic이라는 Class 에서의 AP" 이라는 것을 명심하자
7. mAP (mean Average Precision)
위에서 구한 "Plastic" class에 관한 AP를 구했듯이
다른 "Can", "Paper",... 등등의 class에 관해 AP를 모두 구한 다음 평균을 낸것
FPS (Frames Per Second)
초당 처리하는 frame의 숫자 -> 속도평가
FLOPS (Floating Point Operation)
Model이 얼마나 빠르게 동작하는지 측정하는 metric
연산량의 횟수라고 생각하기 (작을 수록 빠르다)
(일반적으로 덧셈은 FLOPS 계산할 때 빼준다)
Reference
https://www.andrewahn.co/product/using-ml-concepts-in-real-life/
우리는 이미 일상 생활에 머신러닝의 개념을 적용하고 있었다…
Precision과 recall은 머신러닝에서 모델의 성능을 가늠하는 가장 중요한 두 가지 지표이다. Precision은 내가 찾고자 하는 것을 정확하게 찾아내는 능력이고, recall은 내가 찾고자 하는 것을 주어진 표
www.andrewahn.co
https://techblog-history-younghunjo1.tistory.com/178
[ML] Object Detection 기초 개념과 성능 측정 방법
🔊 해당 포스팅에서 사용된 컨텐츠는 인프런의 딥러닝 컴퓨터 비전 완벽 가이드 강의 내용을 기반으로 했음을 알립니다. 설명에서 사용된 자료는 최대한 제가 직접 재구성한 자료임을 알립니
techblog-history-younghunjo1.tistory.com