[Obj Det] Neck (FPN, PANet, RFP, BiFPN, NasFPN, AugFPN)
History
Yolo v1 SSD yolo v2 등이 나오고 다음으로 FPN 이 나오긴 했다
Neck이란
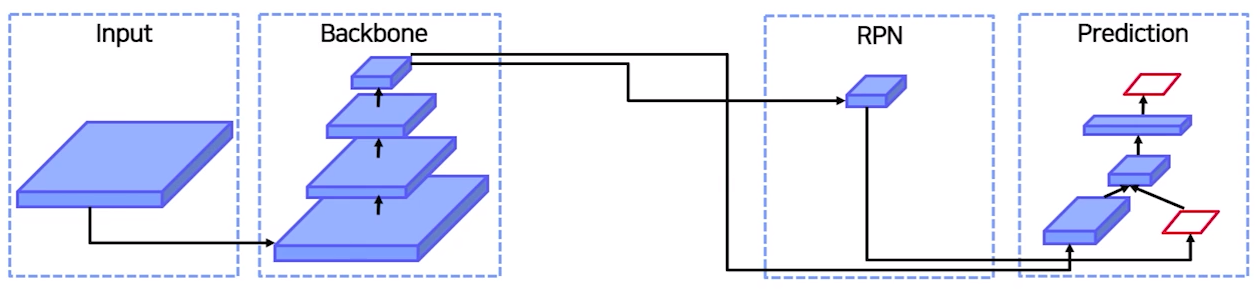
2 stage 인 경우 Backbone의 Feature map을 가지고 RPN에 집어 넣어서 RoI를 뽑아내었음
(Backbone의 마지막 feature map만을 사용)
"왜 꼭 마지막 feature map 만 사용할까?"
"Backbone 중간 중간의 Feature map들을 사용하면 더 좋지 않을까??"
=> 이와 같은 생각으로 Neck이 등장

즉, 중간중간의 Feature map을 뽑아서 Neck으로 넘겨 준다

다음과 같이 bounding box의 크기는 여러개 이다
즉, Neck이 없으면 같은 Feature map에서 다양한 크기의 객체를 예측해야 한다
이렇기 때문에 기존에는 High level feature map에서 RoI Projection을 진행을 하였는데 다음과 같은 문제가 발생
(일반적인 feature map은 Depth가 깊어질 수록 크기가 작아지는 피라미드 구조를 가짐)
High level feature map : 작은 크기의 feature map => 큰 범위를 포함 가능 (깊은 정보를 포함)
low level feature map : 큰 크기의 feature map => 작은 범위를 포함 가능 (점 선 모양 등을 판단)
이렇기 때문에
"Object Detection은 작은 객체를 식별하는 것이 큰 난제이다"
(아직까지도)
즉, Neck은 다양한 크기의 객체를 더 잘 탐지하기 위해서 만들어졌다
<기존의 다양한 시도>
1. 이미지의 사이즈를 단순히 Resize 시켜가면서 학습


2. 마지막 Feature map으로 Projection

3. 중간중간의 Feature map을 바로바로 사용 -> SSD에서 사용할 Idea
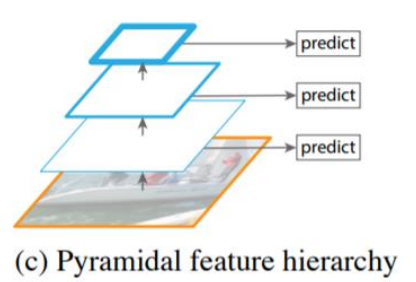
이러면 Semantic 정보가 골고루 섞이지 않는다
Q : 그러면 Neck 없이 바로 Backbone에서 나오는 depth별 Feature map을 바로바로 RPN에 넘겨주면 되자나!
A : 하위 level의 Feature는 Semantic한 정보가 약해서 상위 feature와 섞어주는 것이 좋다
즉, Neck은 Low level Feature map 과 High level Feature map을 공유하게(섞어) 하므로써 정보를 풍족하게 만들어준다
그럼 어떻게 섞어 줄건데???
=> FPN의 등장
FPN(Feature Pyeamid Network)

다음과 같이
Bottom-up 과정 다음에
Top-down path way를 추가해 주었다.
즉, High level의 정보를 low level로 순차적으로 전달
Top-down path way

다음과 같이 bottom up 방식으로 뽑아낸 Feature map들 (P3 ~ P7)을
(* Bottom up은 일반적인 Backbone neuron network를 통과하는 과정이다)
위에서 부터 low level로 전달하는 방식이다
그러면 상위 Feature map을 아래로 어떻게 전달 할 건데
Lateral connection방법으로
Lateral connection
Upsampling 과 1x1 conv를 이용
UPsampling : 이미지 사이즈를 키우는 용
1x1 conv : channel 수를 키우는 용

<Upsampling 방법> : Nearest Neighbor Upsampling

다음과 같이 그냥 2배를 늘려주는 방법이다
왜? : low level feature map의 사이즈는 한단계 위의 feature map 사이즈의 두배 이니깐 (Pooling 때문에)
결과
ex) in_channel : 64 out_channel 128 & Pooling (2x2)
(before)
N depth feature map : 32 x 32 x 64
N+1 depth feature map : 16 x 16 x 128
(after)
N depth feature map : 32 x 32 x 64 ---- (1 x 1 Conv) ---> 32 x 32 x 128
N+1 depth feature map : 16 x 16 x 128 ---- (Upsampling) ---> 32 x 32 x 128
<Backbone> : ResNet 사용 : 4가지 stage 가 존재 (image size가 바뀌는 부분)
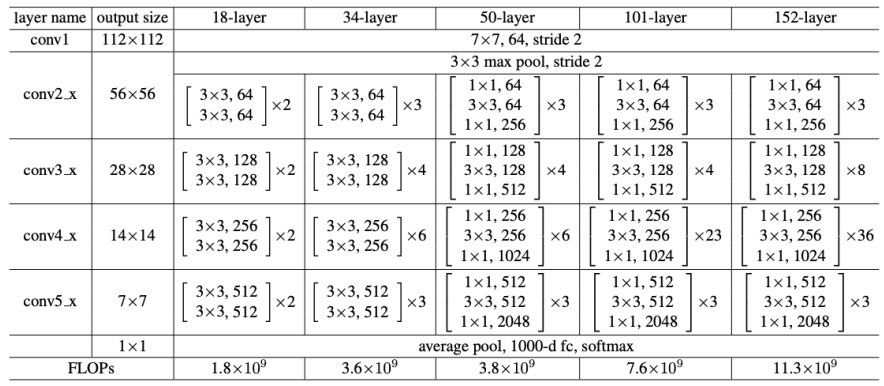
-> 이래서 2배씩 줄었다고 한거임


왜 굳이 224 일까 ? -> ResNet 사용하고 Conv의 Out_Channel이 7의 배수인잔슴
요약
Bottom up -> Feature map 추출
Top down -> Feature map 교류

성능도 좋음
AR : Average Recall
AR 밑에 알파벳 : s : small box, m : middle box, l : large box
구현 (3단계)
Build lateral : Feature map 사이즈 및 차원 맞추기
Build Topdown : Feature map 교환 시켜주기
Build Output : RPN으로 들어갈 input 만들어 주기 (최종 3x3 Conv 통과)
#build laterals
laterals = [
lateral_conv(inputs[i] for i, later_conv in enumerate(self.lateral_convs))
]
#Build top-down
for i in range(3,0,-1): #위에서 부터 아래로
prev_shape = laterals[i-1].shape[2:]
laterals[i-1] += F.interpolate(laterals[i], size = prev_shape)
#윗 단계를 Feature map을 아래단계에 더해준다
#Build output
outs = [
self.fpn_convs[i](laterals[i] for i in range(4))
]
단점
그림은 짧아 보이는데 실제 ResNet은 엄청 길다

즉, low level feature가 high level에 잘 전달이 될까?
(그것도 Conv와 Pooling 연산을 견뎌내면서???)
=> PANet이 등장
PANet (Path Aggregation Network)
위의 문제를 Bottom-up Path Augmentation으로 해결
(그냥 다시 아래에서 위로 보내주는 작업을 해줌)


RPN의 문제점을 해결하고자 함
1. 조금의 차이가 큰 결과를 만들어 버림

단지 이 식으로 RoI가 있던 stage를 예측을 한다고 하면
경계에 있는 RoI에 대해 대응이 불가능 하다
ex) RoI가 10 픽셀 차이인데 어떤건 N3, 어떤건 N4 너무 큰 차이가 발생해버림
2. Projection을 특정 Feature map에만 함
특정 Feature map만 가지고 Projection하는 것이 많은 정보를 활용할 수가 없다.
(이해를 좀 못했지만 약간 low level의 Feature map 이 high level 정보를 담을 수 없다?)
=> 어떻게 해결할 건데
모든 Feature map으로 부터 RoI Projection을 진행하자
기존 RoI에서는 각 feature에서 RoI를 뽑은것과 다르게 전부 다 사용하여 뽑는다.(저기 한점으로 모이자나)
#build output
inter_outs = [
self.fpn_convs[i](laterals[i] for i in range (4))
]
# add bottom up path
for i in range (3):
inter_outs[i+1] += self.downsample_convs[i](inter_outs[i])
outs = []
outs.append(inter_outs[0])
outs.extend([
self.pafpn_convs[i-1](inter_outs[i]) for i in range (1,4)
])
After FPN
DetectoRS (Detecting Objects with Recursive Feature Pyramid)
=> looking and thinking twice
모델이 바로 객체를 뽑아내는 것이 아니라
객체가 있을 법한 위치를 한번 생각하고
class와 box를 뽑아내는 방법
주요구조
RFP(Recursive Feature Pyramid) -> Neck 과 관련되어 있다
SAC(Switchable Atrous Convolution)
RFP (Recursive Feature Pyramid)

앞에서 배운 FPN(Feature Pyramid Network)를 Recursive(반복)하는 것
Bottom-up을 하고 Top-down 까지는 FPN과 동일하지만
여기에 FPN으로 부터 Backbone으로 넘어가는 화살표를 추가해줌
(Neck만 여러개 반복하는 것이 아니라 Neck정보를 Backbone에 전달해서
Backbone도 Neck의 정보를 이용해서 학습가능하도록 의도함)
=> 이러면 Low level backbone이 Top level Feature를 어느 정도 이해함
단점 : Backbone 연산을 다시 반복적으로 하므로 FLops가 엄청 커진다

Backbone -> neck -> 초록색 동그라미를 다시 backbone & neck -> 다시 backbone에 넣거나 predict
backbone과 neck을 통과할 떄마다 하나의 back bone이 만들어진다


F(x) -> FPN연산 B=> backbone 연산
i - 1 번째 stage의 Feature map이 backbone을 통과해서 i 번째 stage의 Feature map이 나온다
그 다음에 high level feature map과 같은 레벨의 Feature map을 lateral(옆쪽) 하게 connection
그 다음 FPN의 결과가 ASPP의 연산(연두 동그라미)을 거쳐서 다시한번 Backbone에 connect된다
즉, Backbone의 두번째 stage는 Backbone의 첫번째 stage와 FPN의 두번째 stage의 결합으로 이루어진다
추가로 FPN의 정보를 Backbone에 그냥 넘겨주는 것이 아니라 ASPP 연산을 거친다
그러면 ASPP가 뭔데!!
ASPP(Atrous Spatial Pyramid Pooling)

-> semantic segmentation에서 배우긴 하지만 Receptive field를 늘리는 방법
(저기서 적혀있는 rate는 dliation rate를 의미)
=> 즉, receptive field를 점점 키워나가면서 pooling 진행하고 concate시켜서 진행
Standard convolution

kernel size = 3x3, stride = 2 Padding =1
=> Receptive field : 3x3
Atrous convolution(dilated convolution)

kernel size = 3x3, dilation rate of 2, stride = 1, Padding = 0
=> Receptive field : 5x5
(Receotive field를 강제로 키우는 연산)
BiFPN
EfficientDet : Scalable and Efficient Object Detection에서 제안

BiFPN은 EfficientDet에서 Neck 부분을 담당
효율성을 위해서(FLops가 너무 높아 속도가 느리다는 것) 위의 그림과 같이 바꿈
-> 한 곳에서만 오는 Node를 제거 (위아래의 가운데 Node를 제거)
이 구조를 계속 쌓아나감
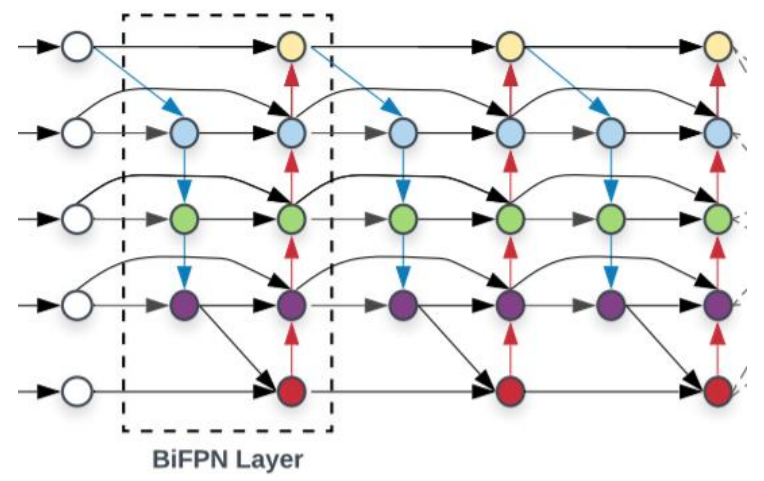
lateral connection 과정에서 단순합을 하는 것에 대해서도 의구심을 품음
Weighted Feature Fusion
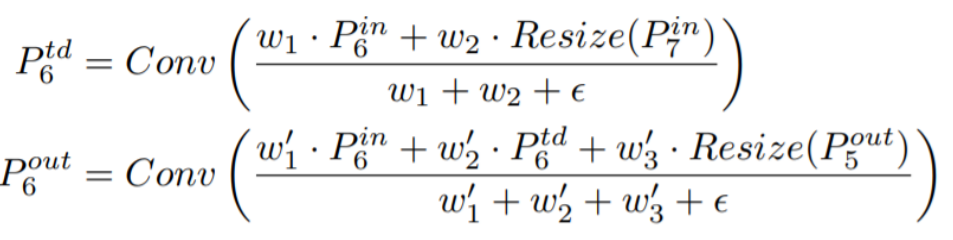
그래서 FPN같이 단순 합을 구하는 것이 아니라 각 Feature별로 가중치를 부여하여서 더해줌
(low level과 high level의 feature를 단순히 섞는 것이 맞는 일이까??)
모델 사이즈는 거의 증가하지 않음
Feature 별로 Weight를 부여하여서 중요한 Feature를 강조하는 효과를 낼 수 있다
결론
속도도 빨라지고 (Node를 제거)
성능도 올렸다 (Weighted Feature Fusion)
NASFPN
Learning Scalable Feature Pyramid Architecture for Object Detection
기존FPN
- 사람이 top-down, bottom up, node 빼기 등을 수동으로 함
- 단순 일방향을 많이 사용함
=> 다양한 구조를 NAS를 통해서 찾을 수 있지 않을까??

기본적인 셀들을 정하고 강화학습이나 유전학습등을 통해 좋은 성능을 낼 수 있는 모델을 찾음
(자세히는 안하고 그냥 NAS를 썼다)

기본 구조 FPN으로 시작해서 AP를 올릴 수있는 경로를 계속 탐색

당연하게 성능이 좋게 나온다
단점
Coco dataset, ResNet기준으로 찾은 구조여서 범용적이지 못하다
심지어 Parameter도 많이 든다
AugFPN
Improving Multi-scale Feature Learning for Object Detection
FPN의 세가지 문제점 제시

1. 서로 다른 level의 Feature간 Semantic 차이
2, Highest level은 이것보다 더 높은 애가 없기에 단순히 Conv연산만 진행(정보손실 생김)
3. 1개의 Feature map에서 Roi 생성 (PANet은 해결하긴 했음)
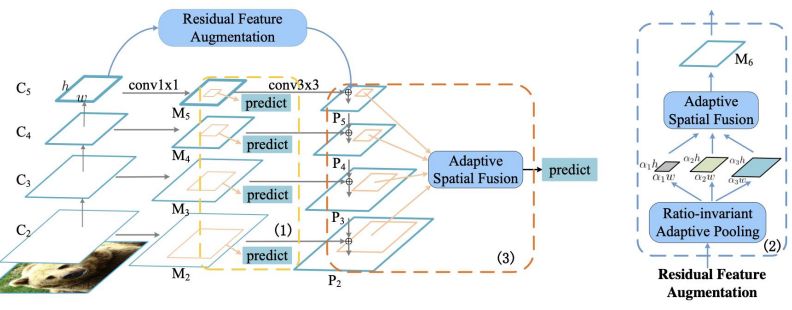
주요 구성
1. Consistent Supervision
2. Residual Feature Augmentation
3. Soft RoI Selection
(이 중 Neck과 관련된 것은 2,3 이다 )
Residual Feature Augmentation
Highest level은 이것보다 더 높은 애가 없기에 단순히 Conv연산만 진행 (P5)
=> 기존 채널이 줄어들게 된다(1x1 conv랑 3x3 conv만 수행하기 때문)
그래서 마지막 stage에 Residual Feature map을 두어 보강을 해줌
Residual Feature는 C5에서 새롭게 M6를 만들고 이를 Top down 시켜줌
그래서 Residual Feature는 어떻게 만들건데!!

C5를 Ratio-invariant Adaptive Pooling으로 다양한 scale의 Feature map을 만들어줌
이렇게 만든 다양한 Feature map을 합칠때는 Adaptive Spatial Fusion을 사용한다
Adaptive Spatial Fusion

Ratio-invariant Adaptive Pooling으로 다양한 scale의 Feature map을 만든 것을
Upsampling을 통해 동일한 사이즈로 맞춰준다
이걸 그냥 더해주면 C5를 사용하는 거랑 별반차이없음
그래서 N개의 Feature에 대해서 가중치를 부여해서 더해준다
conate을 시켜서 conv 연산을 진행하고 sigmoid 연산을 channel에 대해 진행해줌
이러면 각 픽셀별로 N개의 value를 만들어줌(0~1인 sigmoid를 사용하므로 중요도를 포함한다 볼 수 있다)
이렇게 Weight를 만들어 주고
기존의 N개의 Feaure에 대해 가중합을 진행
ex) 3개의 feature map을 concat하고 Nx(1xhxw)를 구함 -> spatial weight
Nx(1xhxw)를 feature를 곱해서 summation
이러면 Residual Feature가 만들어진다
Soft RoI Selection

P2 ~ P5을 통해 RoI를 뽑아야 하는데
FPN은 추출된 RoI에서 stage를 매핑
AugFPN은 모든 Feature에 대해 RoI projection을 진행 (stage mapping 하지않음)

FPN같이 하나의 Feature map에 RoI를 계산하는건 제대로된 방법이 아님
PANet과 같이 모든 Feature map을 사용했지만
Maxpooling을 사용한 PANet과 달리 -> 정보가 손실된다
이를 해결하기 위해 AugFPN은 Soft RoI Selection을 진행
1. 모든 scale의 feature에서 RoI projection을 진행후 RoI pooling
2. channel wise에 대해 가중치 계산후 Weighted Sum을 이용
(즉, PANet의 Max pooling을 Weighted Sum으로 대체하였다)
요약
Feature map을 단순하게 max pooling 하는 것은 비효율적이다
그래서 전부 합치고 싶은데 단순하게 합치는 것도 문제가 된다
그래서 Weighted Sum을 구해야히는데
Weight를 구하는 방법을 4C channel로 맞춰줘서 Channel wise하게 sigmoid진행
이렇게 나온 Weight를 원래 있던 Feature map에 더함
FPN : Top down을 이용하여서 High level Feature를 아래로 전달
PANet : Top down 한다음 Bottom up을 통해 Feature를 섞어줌
RFP : Backbone으로 돌아가서 Backbone을 학습하는 방법,
BiFPN : 서로 다른 level은 서로다른 weight를 주어야 한다 ,
NasFPN : 새로운 구조를 만들어서 해결 ,
AugFPN : Weight를 부여해서 feature map을 섞어줌
Reference
https://better-tomorrow.tistory.com/entry/Atrous-Convolution
Atrous Convolution
Atrous Convolution 1. 일반적인 convolution 2. Atrous convolution(dilated convolution) 위 두 이미지를 한 번 살펴보자 일반적인 convolution과 달리 atrous convolution의 경우 kernel 사이가 한 칸씩 띄워져 있는 것을 확인
better-tomorrow.tistory.com