COCO Format
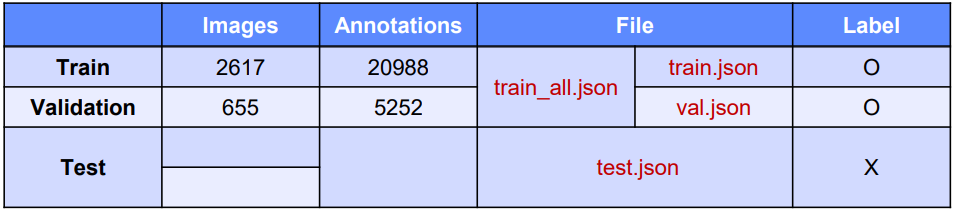
COCO Format은 json 방식으로 제공
train_all.json은 Train과 vaild데이터 셋이 합쳐진거
모든 image는 "batch_01_vt", "batch_02_vt", "batch_03_vt"에 Train/Vaild/Test 구분없이 들어가 있음
(annotation을 확인해보면 이미 저 batch를 포함한 경로로 지정되어 있으므로 그냥 사용하면 될듯하다)
Image의 annotation

1. info
info에는 data set에 대한 high level 정보가 담김

2. licenses

3. images

file_name에 경로와 파일이름이 담겨져 있다
4. categories
해당 image에 해당하는 class에 대한 정보
(class에 해당하는 id,name 및 supercategory가 포함되어 있다)

여기의 id는 class의 masking number이다
categories id 1 에는 General trash가
categories id 2 에는 Paper로 잘 매칭된 것을 볼 수 있다
5. annotations

annotations에 있는
id는 각각의 id (annotation의 고유값)
image_id: annotation이 표시된 이미지 고유 id (이미지의 이름)
segmentation : 전부합치면 색칠한 영역이 나온다 (픽셀단위로 classification을 하기 때문)
Shape of images and targets
Shape of Images : (batch, channel, height, width)
Shape of targets : (batch,height, width)
shape of targets에는 channel이 빠진다
픽셀의 annotation에 대한 class의 값이여서 channel이 필요 없음

Baseline
CustomDataLoader


self.coco = COCO(data_dir)annotation이 들어있는 json파일을 변수로 저장하는 일종의 class 이다.
data_dir : 데이터셋 경로
mode : train / test
- mode = "train" -> (images, masks, image_infos)
- mode = "test" -> (images, image_infos)
여기에서 masks는 segmentation을 그릴 도화지라고 생각하면 편하다
transform: image size 조절 및 data format 변환 등의 전처리 작업
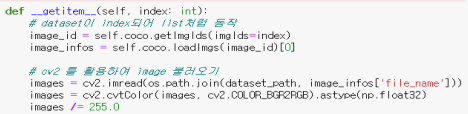
def __getitem__(self, index: int):
#getImgIds를 통해 해당index에서 이미지의 id를 뽑아냄
image_id = self.coco.getImgIds(imgIds=index)
#위에서 뽑은 id를 이용해 이미지에 대한 정보를 얻음
image_infos = self.coco.loadImgs(image_id)[0]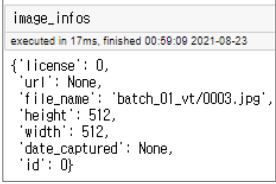
#image1 : 위에서 뽑은 파일경로 dataset_path를 이용하여 이미지를 읽어옴
images = cv2.imread(os.path.join(dataset_path, image_infos["file_name"]))
#image2 : opencv는 BGR로 되어 있기 때문에 RGB로 바꿔야 한다(float단위여서 그림은 이상함)
images = cv2.cvtColor(images, cv2.COLOR_BGR2RGB).astype(np.float32)
#image3 : 이상한 그림을 정상복구 시키기 위해 정규화를 진행
images /= 255.0
if (self.mode in ('train', 'val')):
#image_info의 id를 받음
ann_ids = self.coco.getAnnIds(imgIds = image_infos['id'])
#특정 이미지에 존재하는 annotation 정보 저장
anns = self.coco.loadAnns(ann_ids)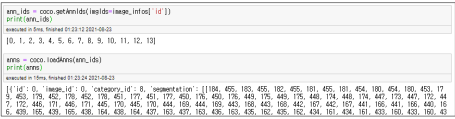
#Load the categories in a variable
cat_ids = self.coco.getCatIds()
cats = self.coco.loadCats(cat_ids)
각 category id가 어떤 재활용 class명을 가지는지


#masks를 0(background)로 채움 ->512 x 512의 빈 numpy 배열
masks = np.zeros((image_infos['height'], image_infos["width"]))
#면적이 큰 순서대로 정렬하기
anns = sorted(anns, key = lambda idx : idx['area'], reverse = True)
#면적이 큰 순서대로 그려주기
for i in range(len(anns)):
className = get_classname(anns[i][category_id],cats) #className을 찍어주고
pixel_value = category_names.index(className)
masks[self.coco.annToMask(anns[i]) == 1] = pixel_value
masks = masks.astype(np.int8)Transform
albumentations library를 활용한 transform을 이용
제공된 baseline에는
train_transform = A.Compose([
ToTensorV2()
])What is ToTensorV2 (??)

Before : numpy (batch, height, weight, channel) - ex -> numpy(8, 512, 512, 3)
After : tensor (batch, channel, height, weight) - ex -> tensor(8, 3, 512, 512)
위와 같이 형태를 맞춰준다
if (self.mode in ('train', 'val')):
...
if self.transform is not None: #transform이 정의되어 있으면
transformed = self.transform(image=images, mask = masks)
#train set은 image와 mask 둘다 가지고 있으므로 둘다 transform을 적용해야 한다
images = transformed["image"]
masks = transformed["mask"]
return images, masks, image_infos
if self.mode == 'test':
if self.transform is not None: #transform이 정의되어 있으면
transformed = self.transform(image=images) #test set은 mask가 없다
images = transformed["image"]
#mask 부분은 필요없다
return images, image_infos #여기에도 mask는 없다Model
torchvision의 model안에 있는 fcn_resnet50을 가져옴
from torchvision import models
model = models.segmentation.fcn_resnet50(pretrained = True)(models의 segmentation에 fcn_resnet50을 부르고 성능향상을 위해 pretrained를 True로 두었다)
하지만 torchvisiion에서 구현된 fcn_resnet50을 살펴보면

output이 21 으로 우리의 task (output = 11)와 맞지 않기에 커스텀을 해준다
model.classifier[4] = nn.Conv2d(512, 11, kernel_size = 1)
loss & optimizer
loss는 기본적으로 softmax와 Cross entropy를 사용한다
#Loss function 정의
criterion = nn.CrossEntropyLoss()optimizer는 Adam을 사용
optimizer = torch.optim.Adam(params = model.parameters(), lr=learning_rate, weight_decay = 1e-6)이렇게 구성된 train code를 살펴보면
def train(num_epochs, model, data_loader, val_loader, criterion, optimizer, saved_dir, val_every, device):
print(f'Start training..')
n_class = 11
best_loss = 9999999
for epoch in range(num_epochs):
model.train()
hist = np.zeros((n_class, n_class))
#Data Loader를 통해 image와 mask를 부르고
for step, (images, masks, _) in enumerate(data_loader):
images = torch.stack(images) # (batch, channel, height, width)
masks = torch.stack(masks).long() # (batch, channel, height, width)
# gpu 연산을 위해 device 할당
images, masks = images.to(device), masks.to(device)
# device 할당
model = model.to(device) #model도 device를 할당해 준다
# inference
outputs = model(images)['out'] #prediction을 생성(image를 모델에 넣어 ouput을 만듬)
# loss 계산 (cross entropy loss)
loss = criterion(outputs, masks) #prediction과 label에 대해 loss를 계산, mask가 GT이다
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''픽셀별로 (batch, channel(cls), height, weight)가 나오는데
target shape는 (batch, height, weight)이므로 mIoU를 계산하기 위해
어떤 class(channel)일 확률이 높은지를 argmax(dim=1)을 이용하여서 (batch,height,weight)꼴로 만든다
outputs = torch.argmax(outputs, dim=1).detach().cpu().numpy()
masks = masks.detach().cpu().numpy()
#mIoU 계산하는 부분
hist = add_hist(hist, masks, outputs, n_class=n_class)
acc, acc_cls, mIoU, fwavacc, IoU = label_accuracy_score(hist)
# step 주기에 따른 loss 출력
if (step + 1) % 25 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{step+1}/{len(train_loader)}], \
Loss: {round(loss.item(),4)}, mIoU: {round(mIoU,4)}')
# validation 주기에 따른 loss 출력 및 best model 저장
if (epoch + 1) % val_every == 0:
avrg_loss = validation(epoch + 1, model, val_loader, criterion, device)
'''지금은 loss가 가장 낮은 애가 best라 되어 있지만
추후에 mIoU가 가장 높은 가중치 point를 저장하는 방식으로 바꾸는 것이 좋다'''
if avrg_loss < best_loss:
print(f"Best performance at epoch: {epoch + 1}")
print(f"Save model in {saved_dir}")
best_loss = avrg_loss
save_model(model, saved_dir)ex)
Output이 (1,4,2,2) -> 실제로는 4개의 class가 아니라 11개의 클래스 이고 w,h 도 다르다
mask가 (1,2,2) 인 상황을 가정
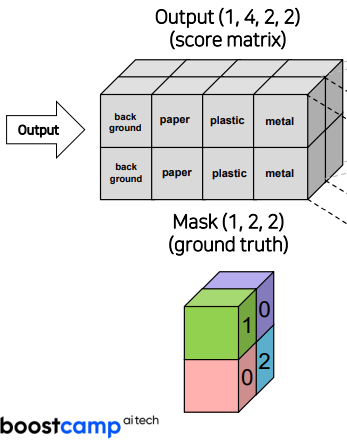
4개의 class에 대한 score값을 구한다

각각의 score에 대해 softmax를 적용시켜서 확률적으로 이용할 수 있도록 한다

다음과 같이 Softmax가 적용된 값에 대해 Cross Entropy를 계산해 준다


loss값이 0.28이 나오게 되고 이를 optimizer를 이용하여 backpropagation을 진행한다
train(num_epochs, model, train_loader, val_loader, criterion, opimizer, saved_dir, val_every, device)를 이용해서 학습을 돌리면
지금의 경우는
train(num_epochs = 20, model= fcn_resnet50, criterion = cross entropy loss, val_every=1, device= 'cuda')
inference & test
위에서 저장 된 path를 불러와서 모든 이미지에 대해 예측을 진행한 후 submission을 만들어야 한다
# best model 저장된 경로
model_path = './saved/fcn_resnet50_best_model(pretrained).pt'
# best model 불러오기
checkpoint = torch.load(model_path, map_location=device)
state_dict = checkpoint.state_dict()
model.load_state_dict(state_dict)
model = model.to(device)
# 추론을 실행하기 전에는 반드시 설정 (batch normalization, dropout 를 평가 모드로 설정)
# model.eval()test를 진행
def test(model, data_loader, device):
size = 256
transform = A.Compose([A.Resize(size, size)])
print('Start prediction.')
model.eval()
file_name_list = []
preds_array = np.empty((0, size*size), dtype=np.long)
with torch.no_grad():
for step, (imgs, image_infos) in enumerate(tqdm(test_loader)):
# inference는 512 x 512로 하고 resize를 이용하여서 256 x 256으로 바꿔서 제출
# inference (512 x 512)
outs = model(torch.stack(imgs).to(device))['out']
oms = torch.argmax(outs.squeeze(), dim=1).detach().cpu().numpy()
# resize (256 x 256)
temp_mask = []
for img, mask in zip(np.stack(imgs), oms):
transformed = transform(image=img, mask=mask)
mask = transformed['mask']
temp_mask.append(mask)
oms = np.array(temp_mask)
#resize할 때 float으로 바뀔 수 있어서 astype(int)를 꼭 넣어줘야한다
#또한 flatten을 시켜주고 중간에 " "를 넣어서 구문 시켜 준다
oms = oms.reshape([oms.shape[0], size*size]).astype(int)
preds_array = np.vstack((preds_array, oms))
file_name_list.append([i['file_name'] for i in image_infos])
print("End prediction.")
file_names = [y for x in file_name_list for y in x]
return file_names, preds_array
mIoU

즉 mIoU란
각 class에 대해 Ground Truth ∩ Predict / Ground Truth ∪ Predict 를 모든 class에 대해 구한 다음 그 값을 평균낸 것
(Background class도 포함한다)
'NaverBoost Camp 4기 > [P stage] Semantic Segmentation' 카테고리의 다른 글
| [P stage][Semantic Seg] 실행코드 (0) | 2022.12.23 |
|---|---|
| [P stage][Semantic Seg] mmsegmentation 설치 방법 (0) | 2022.12.23 |
| [Semantic Seg] U-Net, U-Net++, U-Net 3+ (2) | 2022.12.22 |
| [P stage][Semantic Seg] 대회 프리뷰 & Segmentation 대회 소개 (마스터 클래스) (0) | 2022.12.21 |
| [P stage][Semantic Seg] 대회 환경세팅 (0) | 2022.12.21 |



