자 묻지도 따지지도 말고 라이브러리 부터 다운 받읍시다
pip install beautifulsoup4
pip install lxml저 두번째 꺼는 엘 엑스 엠 엘 임ㅇㅇ...
자 네이버 웹툰의 url을 가져 옵시다

import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")마지막 줄은 우리가 url 로 가져온 res를 lxml을 통해서 BeatifulSoup 객체로 만듬
이러면 soup에 모든 정보를 가지고 있다
다음과 같은 예시를 보자
print(soup.title)
다음과 같이 있고 이를 확인해보면

저 부분을 그대로 가져온 것을 볼 수 있다
글자만 빼고 싶으면
print(soup.title.get_text())
링크들이 걸려있는 a를 확인해보자

모든 a를 가져오는 것이 아니라 첫 번째로 발견되는 a 를 출력해준다
하지만 저러면 속성만 보고 싶을때 불편하다
print(soup.a.attrs)
조금 더 깔끔하게 볼 수있다 (딕셔너리 형태로)
접근은 딕셔너리 처럼
print(soup.a["href"])
정리
- soup.a : soup객체에서 처음 발견되는 a element
- soup.a.attrs : a element의 속성 정보
- soup.a["속성값"] : a element의 href 속성 '값' 정보
하지만 이 페이지에 대해 이해를 기반하는데 난 웹 잘 몰라!!!
find()
저 웹툰 올리기 버튼을 가지고 오고 싶다고 가정하자
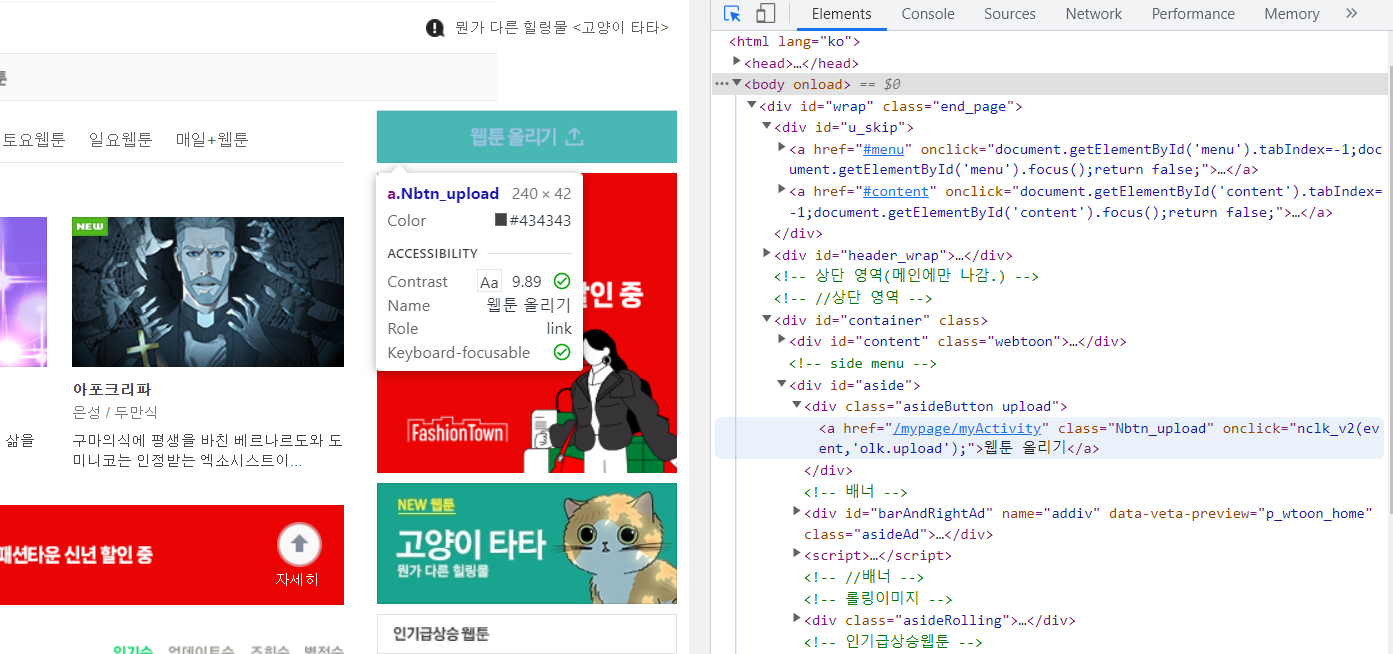
오 class= "Nbtn_upload" 가 고유값일거 같은걸?
soup.find("a")a tag에 해당하는 첫 번째 엘리먼트를 가져온다

그래서 내가 원하는 것이 아닌 첫 번째를 가져오게 된다
이를 막으려면
조건을 추가하면 더 정확하겠죠 ??
print(soup.find("a", attrs = {"class" : "Nbtn_upload"}))-> class = "Nbtn_upload"인 a element를 찾아줘

사실 Nbtn_upload는 한개여서 "a" tag를 굳이 안적어도 된다
print(soup.find(attrs = {"class" : "Nbtn_upload"}))class = "Nbtn_upload"인 어떤 element를 찾아줘
이번엔

인기 급상승 1위를 가져온다 가정해 보자
element 이름은 li tag 인 것을 볼 수 있다
print(soup.find("li", attrs = {"class" : "rank01"}))
오우 쉿 ;; 연애혁명 가져옴!!
근데 나는 링크만 알면 되는 걸...
그럴땐 링크가 a 였으므로
rank1 = soup.find("li", attrs = {"class" : "rank01"})
print(rank1.a)
a href 에대한 정보만 가져왔다
"Soup 도 tree 구조 이다" (부모 형제 자식 존재)
next_sibling : 다음 element를 불러옴
다음 코드를 실행시켜보자
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")
rank1 = soup.find("li", attrs = {"class" : "rank01"})
print(rank1.a.get_text())
print("-------------------")
print(rank1.next_sibling)#다음 element로 넘어감
print("-------------------")
print(rank1.next_sibling.next_sibling)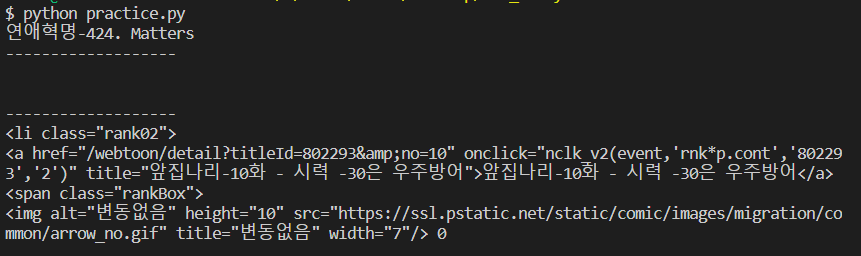
중간 sinbling은 중간에 개행 정보 등에 의해 아무 정보도 출력되지 않은 것을 볼 수 있다
이렇게 인기순위 10개를 가져올 수 있다

다음을 가져오는 코드를 간단히 짜보면
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")
tmp = soup.find("li", attrs = {"class" : "rank01"})
for rank in range (1,11):
print("rank", rank, " : " ,tmp.a.get_text())
tmp = tmp.next_sibling.next_sibling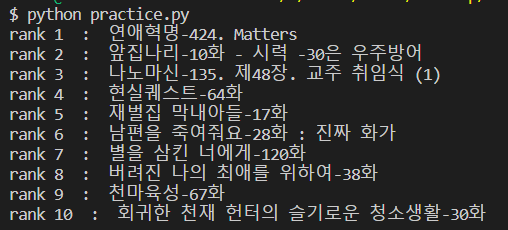
정상적으로 가져올 수 있는 것을 볼 수 있다
반대 과정은
previous_sibling : 이전 element를 불러옴
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")
rank1 = soup.find("li", attrs = {"class" : "rank01"})
print(rank1.a.get_text())
print("-------------------")
print(rank1.next_sibling)#다음 element로 넘어감
print("-------------------")
print(rank1.next_sibling.previous_sibling.a.get_text())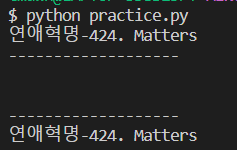
내려왔다가 다시 올라간것을 확인 할 수 있다
근데 저 개행때문에 개빡치는게
print(rank1.a.get_text())
print("-------------------")
print(rank1.next_sibling.a.get_text())#다음 element로 넘어감
print("-------------------")
print(rank1.next_sibling.previous_sibling.a.get_text())를 한다면
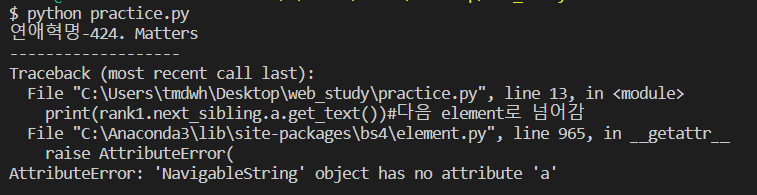
중간에는 a 가 없어서 오류가 난다
이를 해결하는 것이
find_next_sibling()
next sibling 이긴 한데 조건에 맞는 녀석만 찾아줌
print(rank1.a.get_text())
print("-------------------")
print(rank1.find_next_sibling("li").a.get_text())#다음 element로 넘어감
print("-------------------")
print(rank1.next_sibling.previous_sibling.a.get_text())다음과 같이 적으면 li 가 있는 녀석만 가져오기 때문에

오류가 해결이 된다
이를 통해 위의 코드를 좀더 깔끔하게 나타내면 (솔직히 next_sibling.next_sibling은 오바자나)
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")
tmp = soup.find("li", attrs = {"class" : "rank01"})
for rank in range (1,11):
print("rank", rank, " : " ,tmp.a.get_text())
tmp = tmp.find_next_sibling("li")로 바꿀 수 있다
당연히 find_previous_sibling도 있다
근데 내가 순위가 10개인지 어떻게 알아!!
그래서 사용하는 것이
find_next_siblings -> 형제들을 가져와줌
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")
tmp = soup.find("li", attrs = {"class" : "rank01"})
print(tmp.find_next_siblings("li"))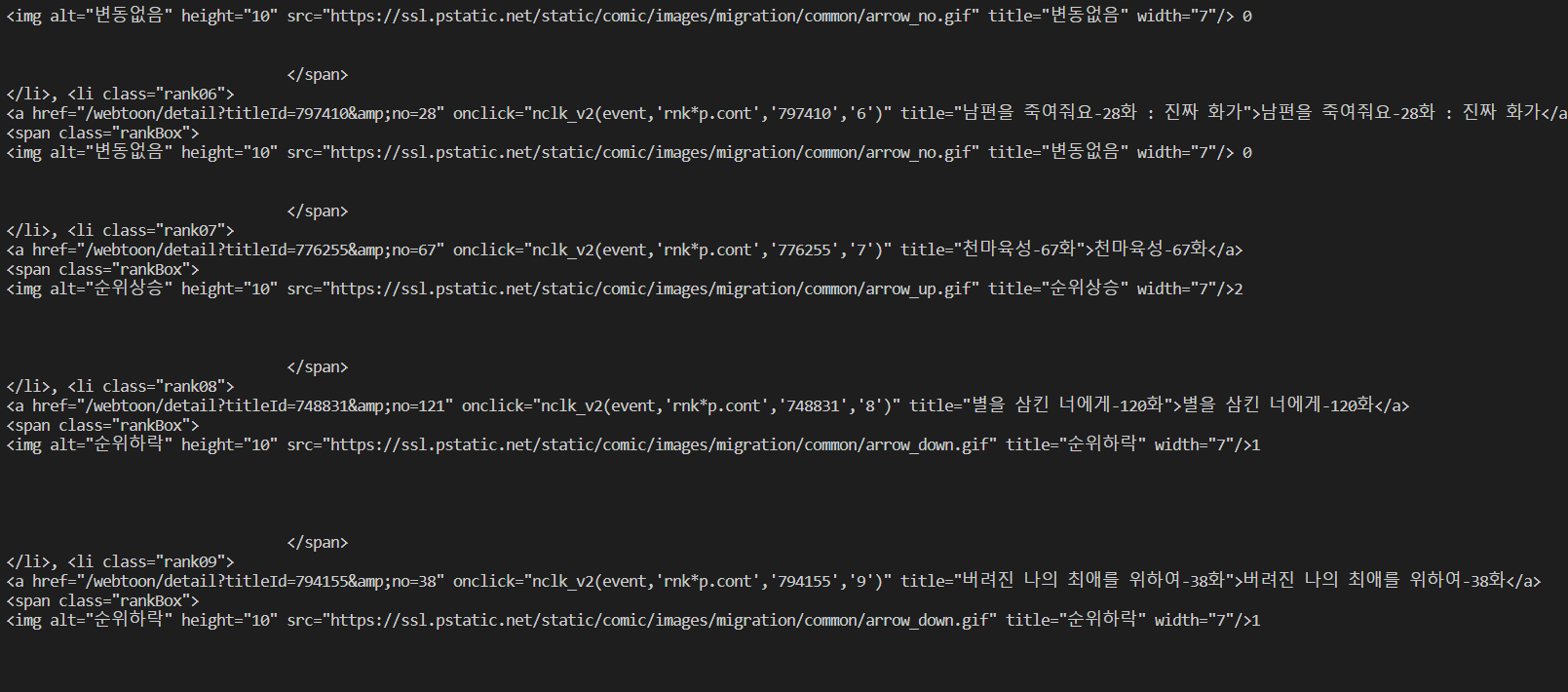
find 의 또다른 기능은
<a onclick="nclk_v2(event,'rnk*p.cont','570503','1')" href="/webtoon/detail?titleId=570503&no=429" title="연애혁명-424. Matters">연애혁명-424. Matters</a>
인데 여기에서 <a 로 열고 </a>로 닫은 것 중
<a onclick="nclk_v2(event,'rnk*p.cont','570503','1')" href="/webtoon/detail?titleId=570503&no=429" title="연애혁명-424. Matters">연애혁명-424. Matters</a>
이 부분이 text 이다
그래서 print를
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status #못가져올시 프로그램 종료되게
soup = BeautifulSoup(res.text, "lxml")
tmp = soup.find("a",text = "연애혁명-424. Matters")
print(tmp)이렇게 해서

역으로 찾아낼 수 있다
parent : element의 부모를 불러옴
print(rank1.parent)출력은 길어서 생략
진도체크
chapter 11까지 들음
'Python > Application' 카테고리의 다른 글
| [Python] Streamlit 활용 전 정리 (0) | 2024.06.05 |
|---|---|
| [Data Scraping] Error : Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same (0) | 2023.02.10 |
| [Data Scraping] 구글에서 고화질 이미지 스크래핑(크롤링) - selenium (0) | 2023.01.27 |
| [Scraping] HTML, XPath, Requests,정규식 찍먹해보기 (+User-agent) (1) | 2023.01.19 |

