< 자연어 처리에 대한 이해 >
자연어 처리를 이해하기 위해서는 사람과 사람의 대화를 분석해 볼 필요가 있다

A 와 B 가 대화를 하고 A가 어제 본 나무를 설명하는 상황이라 가정을 해보자
먼저, A라는 사람은 어제 본 나무를 "Tree"라는 언어로 바꿔서 말을 하기 시작할 것이다
이 과정을 " Encoding " 이라 할 수 있다
-> 즉, 컴퓨터에 입장에서는 " 어제 본 나무 = 자연어 " , " Tree라는 단어 = 수학적으로 표현된 좌표평면 위에 벡터 "
라고 치환을 해볼 수 있다
Encoding 이란 자연어를 수학적으로 표현 할 수 있도록 좌표평면 위에 벡터로 표현하는 방법을 말한다
이러한 Encoding 과정을 거치는 이유는 우리가 좌표평면 위에 벡터로 표현을 할 수 있으면 분류나 Feature Extraction 등을 다양하게 이용할 수 있기 때문이다
그러면 B라는 사람은 A가 말하는 "Tree"라는 언어를 듣고 머리 속에서 나무를 떠올릴 것이다
이 과정을 " Decoding " 이라 할 수 있다
-> 즉, 컴퓨터에 입장에서는 " Tree라는 단어 = 좌표평면 위에 벡터 " , " 머리 속에 떠올리는 나무 = 자연어 "
라고 치환을 해볼 수 있다
Decoding 이란 수학적으로 표현된 벡터를 가지고 자연어로 치환하는 방법을 말한다
위에 과정에서 제일 중요해 보이지만 그것이 가능할까? 라는 단계가
자연어를 수학적인 벡터로 표현하는 것이다
이 과정을 우리는 " Embedding " 과정이라고 한다
< 자연어 단어 임베딩>
유명한 방법 2가지를 소개해 보자면
- Word2vec
- FastText
위에 언급은 되지 않았지만
가장 쉬운 방식은 One-hot-encoding 방식이다
만약 "슬픈 대학원 생활"
이라는 문장이 있을 때
이를
슬픈 = [1,0,0]
대학원 = [0,1,0]
생활 = [0,0,1]
이렇게 나타낸다면 n개의 단어는 n차원의 벡터로 표현이 가능할 것이다
하지만 이 방식을 Sparse(부족한) representation이라 부르는 이유는
그냥 한 차원에 하나의 단어를 올리는 이러한 one hot encoding 방식은
단어가 가지는 "의미"를 표현할 수가 없어서 단어 사이의 "관계"를 알 수 없는 단점이 있다
이를 보완 하기 위해 Word2vec가 등장하였다
Word2vec를 간략하게 소개해보면
<Word2Vec>

Word2vec에 대한 이론은 추후에 정리를 하는 것으로 하고
개념과 장단점만 알아보고 넘어가자
Word2vec의 가장 핵심 idea는
단어가 가지는 의미자체를 벡터 공간에 임베딩 하는 방법이다
어떻게 단어가 가지는 의미를 벡터공간에 나타낼 수 있을까
중심 단어와 주변 단어들을 이용하여 학습을 한다
즉, 중심 단어의 주변 단어들을 이용하여 중심단어를 추론하는 방식으로 학습한다
-> 이러면 단어간의 유사도 측정에 용이하고 관계 또한 파악이 가능하다
-> 더욱 신기한 것은 벡터 상의 값이므로 단어끼리의 연산이 가능하다
ex) 할아버지 - 할머니 + 물 = 기름
-> 할아버지 - 할머니를 하면 서로 반대되는 요소만 남게 되고 여기에 물을 넣으면 word2vec이 생각하는 물의 반댓말을 알 수 있다
그러면 좋은 점만 있는 것 같지만 치명적인 단점이 있다
제일 먼저 단어의 subword information을 무시한 다는 것이다 (car과 cars를 아예 다른 단어로 취급)
즉, 다양한 용언 표현들이 서로 독립된 vocab로 관리 된다는 단점이다
가장 치명적인 단점은
OOV (Out Of Vocabulary)
즉, 학습에 사용된 단어 외에는 추론이 불가능한 단점있다
그래서 나온 방법이 FastText이다
<FastText>
FastText는 Facebook Research에서 공개한 Open source library이다
(https://research.fb.com/fasttext/, fastText)
FastText는 subword Information에 집중해 만들어진 Word2vec 알고리즘이고
Training 방식에 있어서 word2vec과 차이가 있다
단어를 n-gram으로 나누어서 학습을 진행한다
n-gram이란 무엇일까?
예시를 들으면 굉장히 쉽다
Orange로 2-gram의 예시를 들어보면
<O, Or, ra, an, ng, ge, e> 이렇게 앞에서 부터 2개씩 읽는 다고 생각하면된다
꺽쇠는 단어의 시작과 끝을 구분하기 위해 사용한다
이렇게 했을 때의 장점은 OOV에 대한 대처가 강하다는 것이다
밑에 Orange로 학습된 모델을 예시로 들어보면
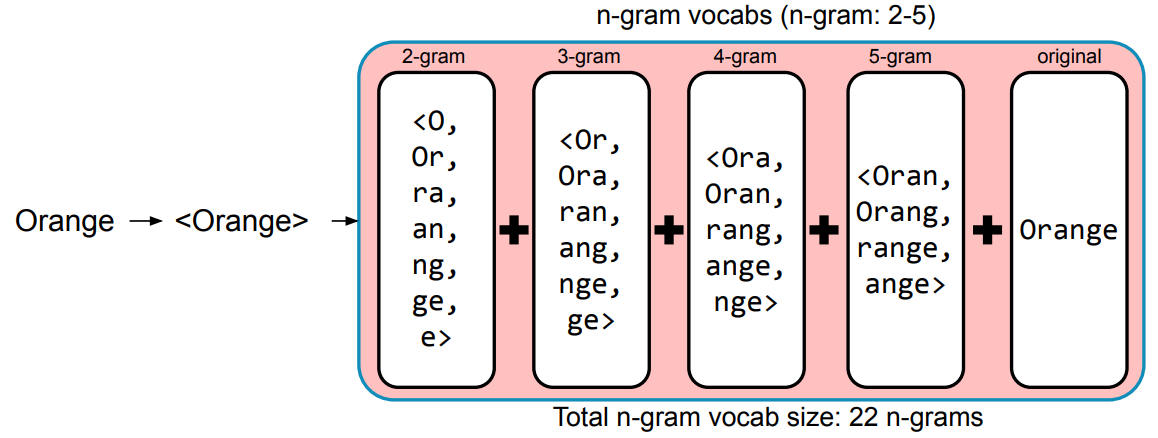
여기에 OOV인 Oranges 가 들어온다고 할 때

빨강 부분을 빼고 많은 요소들이 겹쳐 있으므로 similar 하다고 판단이 가능하다
즉, FastText는 단어를 n-gram으로 분리를 한 후, 모든 n-gram vector를 합산 후 평균을 통해 벡터를 획득한다
이러한 방법을 채택하기에 오탈자와 OOV, 등장 횟수가 적은 단어에 대해 강세를 보인다

하지만 여전히 해결하지 못하는 단점이 존재한다
Word Embedding 방식은 동형어, 다의어 등에 대해서는 성능이 좋지 못하다
즉, 주변단어를 통해 학습이 이루어지기 때문에 "문맥"을 고려할 수 없다는 단점을 지닌다.
이를 해결하기 위해 언어모델이 등장한다
< 언어 모델 >
언어 모델이란?
자연어의 법칙을 컴퓨터로 모사한 모델
주어진 단어로 부터 그 다음에 등장한 단어의 확률을 예측하는 방식으로 학습
좋은 언어 모델이다 ? -> 언어의 특성이 잘 반영되어 있다, 문맥을 잘 계산한다
1. Markov Chain Model
Markov chain model (마코프 체인 모델, Markov 기반의 언어 모델)
가장 전통적인 방식 -> 단어의 n-gram을 기반으로 계산
딥러닝 기반의 언어 모델은 해당 확률을 최대로 하도록 네트워크를 학습

위의 계씨는
I like rabbits
I like turtles
I don't like snails
이렇게 3개의 문장을 학습했을 때의 예시이다
다음과 같이 학습이 되었을 때
I 다음에 나오는 단어로는 like가 0.66 don't가 0.33이므로 더 높은 확률인 like가 나오게 된다
2. RNN 기반의 언어모델
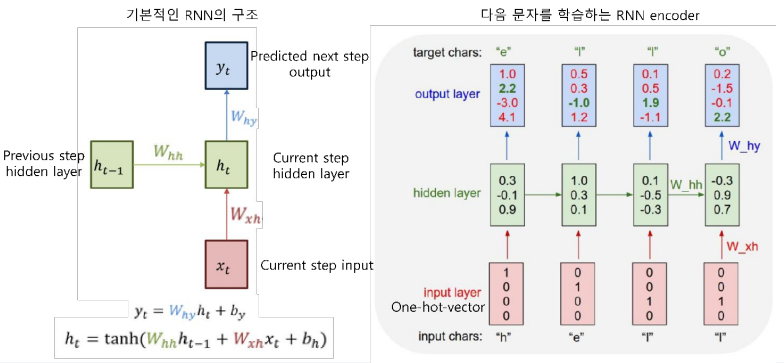
이전 State의 정보가 다음 state를 예측하는데 사용 되기 때문에 시계열 데이터 처리에 유리하다
마지막 출력은 앞선 모든 단어들의 "문맥"을 고려해서 만들어진 vector (context vector) 이다
출력된 Context vector 값에 대해 classification layer를 붙이면 문장 분류를 위한 신경망 모델이 된다

이러한 방식으로 여러가지를 만들 수가 있는데
다음 과 같이 input 과 output의 개수에 따라서
세가지의 경우로 나눌 수 있다

one to many 방식은 이미지 캡셔닝 (이미지가 어떤 걸 나타내는지)
many to one은 문장 분류
many to many는 개체명 인식 등에 사용이 된다
2. RNN 기반의 Seq2seq
Encoder : RNN 구조를 통해 Context vector를 만들어낸다
Decoder layer : Encoder에게 context vector를 받아서 Decoding하여 출력을 만들어 낸다

Context vector가 Decoder에 입력으로 들어와서 Nan 이란 출력을 만들어 내고
Nan 이 다시 Decoder에 들어가서 nul 이라는 출력을 만들어 내고
다시 nul이 Decoder에 들어가는 방식이다
하지만 다음과 같은 문제점
- 입력 sequence의 길이가 매우 긴 경우 앞써 token에 대한 정보가 희석됨 (Short term Dependency)
- 고정된 context vector size 때문에 sequence 정보에 대한 함축이 어려움
- 모든 token이 영향을 주어서 불필요한 token까지 요약을 함 -> 우리가 책을 읽을 때도 모든 단어가 중요하진 않자나
그래서 나온 것이 Attention : 모든 token을 보지 말고 중요한 정보만 봐 보자 라는 컨셉이다
3. Attention 기반의 Seq2seq
RNN은 가장 마지막 출력인 context vector에만 관심을 가졌지만
Attention은 지나쳐온 token의 hidden state의 vector값을 활용한다
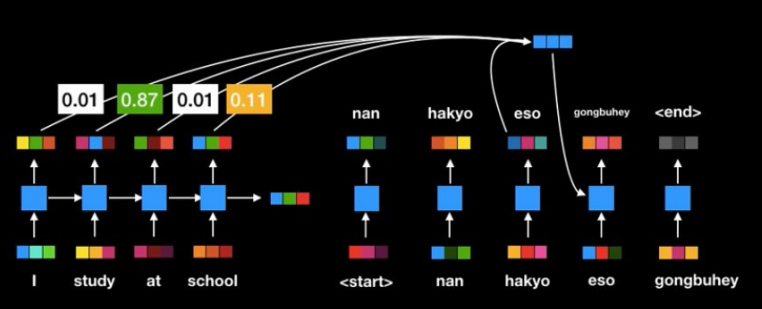
하지만 여전히 RNN 구조를 채용하고 있기 때문애
연산 속도가 느리다는 문제점은 해결하지 못하였다
ex) I 를 한번 하고 끝나면 Study하고 끝나고 at 처리하고 ,,,,,,
4. Self-Attention 기반의 Seq2seq
이전 state를 다음 state로 넘기는 구조를 없애고 모든 token을 연결 시킨다

저 one step matrix multiplication 부분이 self - attention 이다
transformer에 관한 자세한 설명은
[DL Basic] Transformer (Attemtion is All You Need).2017
Tranformer는 엄밀하게 말하면 앞에서 연결되는 RNN, LSTM, GRU와는 좀 다른 방법으로 접근한다 -> 해결하고자 하는 것은 동일함 왜 Sequential modeling이 다루기 어려울까? 우리의 일상생활을 생각해보자
aisj.tistory.com
Transformer의 Architecture를 보면
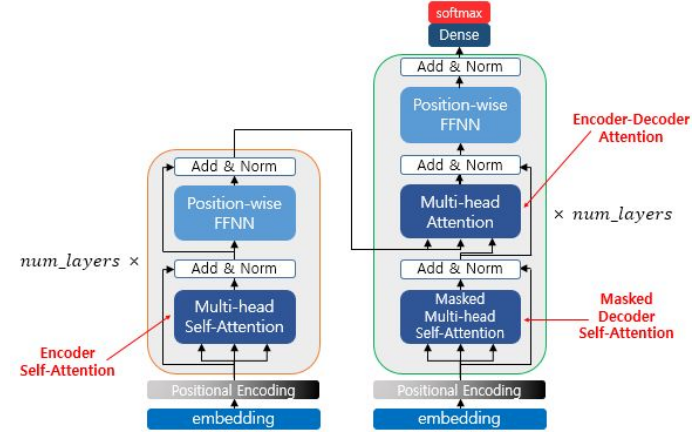
다음과 같은 구조를 가지게 된다
이러한 구조 덕분에

기존 seq2seq model은 Encoder 와 Decoder를 따로 만들어야 했지만
Transformer는 하나의 Network 내에 Encoder와 Decoder를 합쳐서 구성할 수 있고
이는 엄청난 혁신을 가지고 왔다