초반에는 Orion의 AER 모델을 사용하다가 모델 성능은 좋지만
GPU 메모리 사용량과 추론 시간이 너무 오래 걸려서 PyOD를 검토
1. 초기 설정
해당 링크에 오픈소스로 공개되어 있다
https://github.com/yzhao062/pyod/tree/master
GitHub - yzhao062/pyod: A Python Library for Outlier and Anomaly Detection, Integrating Classical and Deep Learning Techniques
A Python Library for Outlier and Anomaly Detection, Integrating Classical and Deep Learning Techniques - yzhao062/pyod
github.com
추가로 공식문서가 있으니 이거 따라하기만 하면 된다
https://pyod.readthedocs.io/en/latest/install.html
- 라이브러리 다운로드
설치의 경우 다른 라이브러리처럼 다운로드하여 사용가능하다.
pip install pyod
사용하는 방법은 라이브러리이기 때문에 import 해서 사용하고
자세한 것은 아래 링크를 참고하자
https://pyod.readthedocs.io/en/latest/pyod.html
모델별 정리
지원하는 모델을 다 보려면 너무 많다
그래서 이중에 몇 개만 살펴보자
ABOD, ALAD, AnoGAN, AutoEncoder, CBLOF, COF, CD, CDPOD, DeepSVDD, ECOD, FeatureBagging, GMM, HBOS, IForest, INNE, KDE, KNN, LMDD, LODA, LOF, LOCI, LUNAR, LSCP, MAD, MCD, MO_GAAL, OCSVM, PCA, RGraph, ROD, Sampling, SOD, SO_GAAL, SOS, SUOD, VAE, XGBOD

이건 2차원일때 다음과 같이 나오고
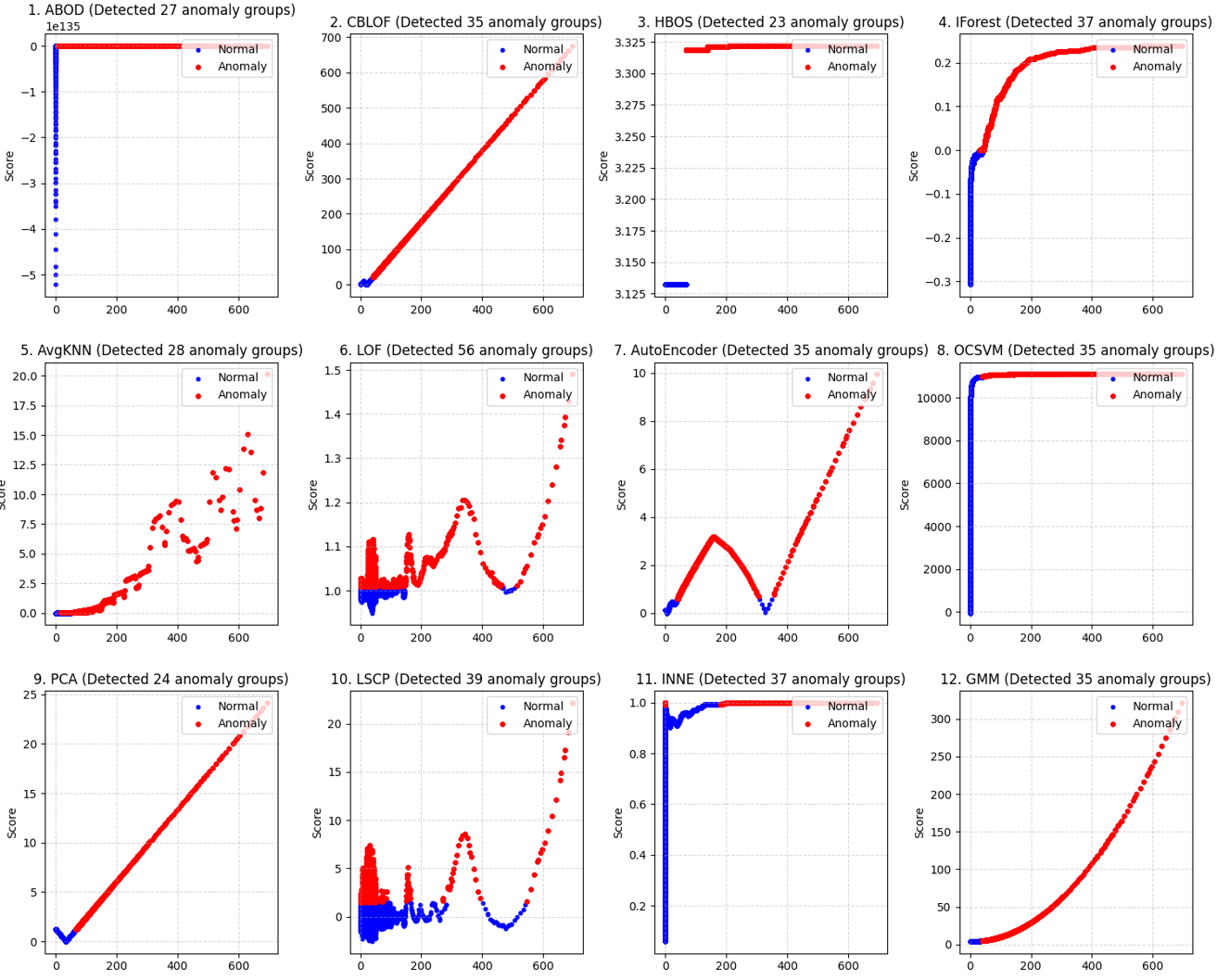
일차원 그래프는 다음과 같이 나온다
여기서 약간 바꿔서 나는
classifiers = {
#'ABOD': ABOD(contamination=outliers_fraction),
'CBLOF': CBLOF(contamination=outliers_fraction, check_estimator=False),
#'FeatureBagging': FeatureBagging(LOF(n_neighbors=35), contamination=outliers_fraction),
'HBOS': HBOS(contamination=outliers_fraction),
'IForest': IForest(contamination=outliers_fraction),
'KNN': KNN(contamination=outliers_fraction),
'AvgKNN': KNN(method='mean', contamination=outliers_fraction),
'LOF': LOF(n_neighbors=35, contamination=outliers_fraction),
'AutoEncoder' : AutoEncoder(epoch_num=30, contamination=outliers_fraction),
#'MCD': MCD(contamination=outliers_fraction),
'OCSVM': OCSVM(contamination=outliers_fraction),
'PCA': PCA(contamination=outliers_fraction),
#'LSCP': LSCP(detector_list, contamination=outliers_fraction),
'INNE': INNE(contamination=outliers_fraction),
'GMM': GMM(contamination=outliers_fraction),
# 'KDE': KDE(contamination=outliers_fraction),
#'LMDD': LMDD(contamination=outliers_fraction),
}이렇게 12개의 모델을 Test 햇다
알아두면 좋은 것들이니 간단하게 살펴보도록 하자
ABOD (Angle-based Outlier Detiction)
https://www.researchgate.net/figure/Angle-Based-Outlier-Detector-ABOD_fig4_362868330
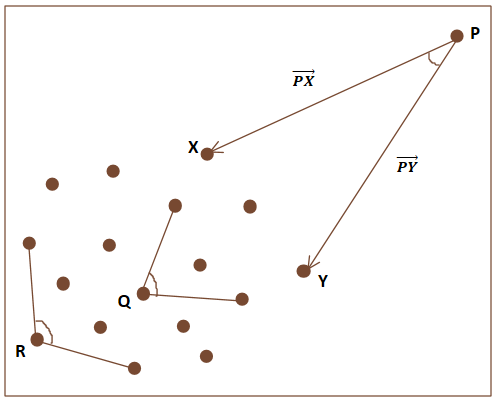
- 각도 기반의 이상치 탐지 알고리즘
- P(이상점)의 경우 나머지 어떤 두 점을 잡아도 각도이 작다 (즉, 각도의 분산이 작아진다)
- 이걸로 이상치를 구분해 낸다
- 고차원에서도 거리기반 이상치 탐지 보다 좋은 성능을 가짐
- 하지만 이상치가 많아서 다른 이상치들에게 둘러 싸인 경우 정상객체와 구별이 어렵다
LOF (Local Outlier Factor)

근처에 있는 데이터의 분포에서 얼마나 떨어져 있는지 판단 (밀도 기반)
- 대부분의 이상치 탐지 알고리즘은 o2를 잘 잡아내지 못함 (o1은 모두 잘 잡아냄)
- 이를 해결하기 위해 밀도 기반의 국소적 정보를 이용하는 LOF를 사용

2.5677의 값을 가지는 애도 원래 못잡았을 텐데 밀도를 기반으로 산출을 해서 잡을 수 있다
CBLOF (Cluster-based Local Outlier Detiction)

위에 LOF 관련 설명을 보면 궁금한 점이 생긴다.
- 만약 이상치 들이 모여 있다면???
- 예를 들어 C3 은 이상치 인데 모여있으니 이상치라고 안나올 수도 있다
- C1은 이상치로 봐야 할까
- 이를 해결하기 위해 이상치를 클러스터 단위로 판단 (클러스터 크기와 거리)
- 전체 데이터의 약 90%에 포함되는 클러스터를 큰 클러스터 나머지는 작은 클러스터로 취급
- 설정에 따라 이 작은 클러스터 전체가 이상치로 판단될 수 있다 (큰 클러스터에서 멀리 떨어져 있으면)
- 소수의 비정상 그룹을 찾는데에 효과 적임
HBOS (Histogram-based Outlier Score)
한 줄로 요약하면 "빈도 기반의 이상치 탐지"
https://www.dfki.de/fileadmin/user_upload/import/6431_HBOS-poster.pdf
- 각 변수별 히스토그램을 그려 outlier score를 그린다
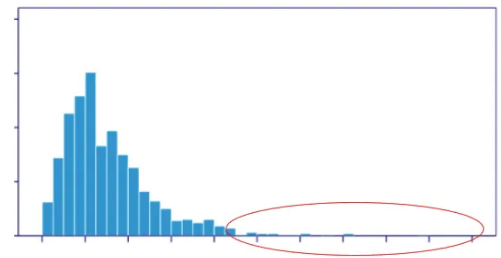
- y축은 빈도 수라고 봐도 된다
- 동그라미 친 빈도 수가 낮은 애들은 이상치라고 판단 한다
- 대규모 데이터 셋에 특화 되어 있고 거리 계산이 없어서 빠르다
- 변수간의 상관관계는 모르겠고 냅따 빈도만 따지기 때문에 다변량 이상치(Multivariate Outlier를 놓칠 수 있음)
IForest (isolation forest)
https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf?q=isolation-forest

- 해당 데이터가 의사결정나무를 몇 회를 타고 내려가서 고립되는지 기준으로 이상치와 정상치를 분리
- 이상치라는 것은 애초에 정상치랑 떨어져 있기 때문에 몇번 안 내려가도 분리가 된다

KNN (K Nearest Neighbors)
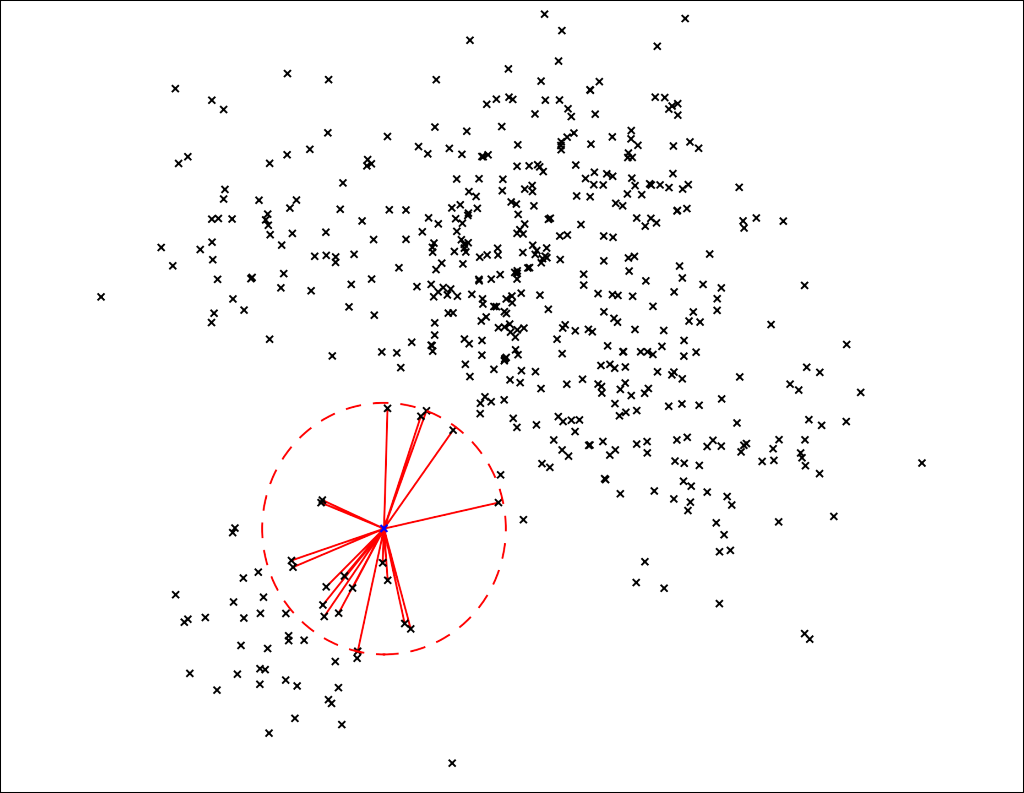
보통 KNN을 하면 라벨이 없는 데이터를 K개의 군집으로 묶는 방법을 떠올리는데
이거를 Anomaly에 이용하면 주변에 K개의 이웃들의 거리를 구해서 이 거리의 합이 멀면 이상치 이다 라고 말하는 것이다

이런 식으로 이용
AVGKNN (Average K Nearest Neighbors)
위에서 말한 KNN들중 method를 "mean"으로 설정하여서 사용한다
즉, 이웃한 K개의 점들의 거리의 평균을 통해 이상치를 탐지하는 방법이다
KNN(method='mean', contamination=outliers_fraction)
AE (AutoEncoder)

Encoder-Decoder를 사용하여서
Encoder 가 Feature 들을 압축해서 Bottleneck Layer로 전달하고
Decoder 가 복원을 하여 원본가 차이가 많이 나는 놈은 못 보던 놈이니 이상치라고 하는 방법이다
입력샘플과 복원 샘플의 오차를 (Reconstruction Error) 라고 한다

PCA (Principal Component Analysis)
이것도 Reconstruction 방식이여서 AE 밑에다가 작성을 하였다
이건 원본 데이터의 분산을 최대한 보존하는 축을 찾고 그 축에 데이터를 Projection 시키는 것이다

그 다음 이 Projection 된 데이터를 다시 복원하여 Reconstruction Error 가 큰 놈을 이상치라고 한다


OCSVM (One class Support vector Machine) 1-SVM

- Support Vector Machine 이란 여백 (Margin)을 최대화 하는 초평면(Hyperplane)을 찾는 것이다
- 초평면이라 한 이유는 feature 가 두 개면 선으로 구분 세개면 평면으로 구분 그 이상이면 초평면으로 구분하기 때문
- Margin(여백) : Support Vector machine의 핵심이다.
- 주어진 데이터가 오류를 발생시키지 않고 움직일 수 있는 최대의 공간

여기서 이상한 것은 SVM은 지도 학습이다 - 이걸 어떻게 비지도 학습에 이용 할까
OCSVM은 말 그대로 class가 정상과 비정상 밖에 없으며 정상 밖에 있는 애들을 이상치로 분류한다
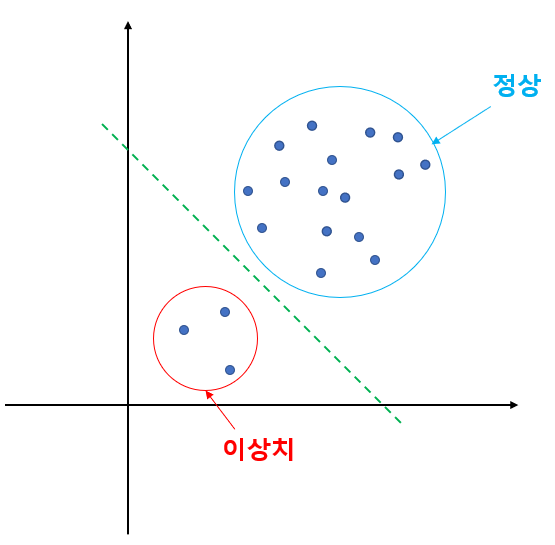
어떻게 정상인지 이상치인지를 구별하나면
"정상 데이터만을 사용해 학습" 이라는 조건이 붙는다
이 학습된 데이터를 이용해서 원점으로 부터 데이터를 최대한 분리하는 초평면(Hyperplane)을 찾는 것이다

이렇게 초 평면에서 멀리 떨어진 애들을 이상치로 감지하는 알고리즘이다
- 나 같은 경우는 train data도 어떤게 정상인지 비정상인지 알 수 없어서 성격이 맞지 않는다
GMM (Gaussian Mixture Model)
- 데이터가 여러 개의 가우시안 분포(Gaussian distributions)의 혼합으로 구성되어 있다고 가정을 하고
- 각 분포의 평균(mean), 분산(Variance) 그리고 비중(혼합 계수, Mixture coefficients) 등의 파라미터로 정의
- 즉, Train set 을 이용해서 여러 개의 가우시안 분포 들을 만들고 Test Set이 여기에 골인 하냐 안하냐로 따지는 것

아래가 이걸 이용한 것 같다
https://sseozytank.tistory.com/144
[ML] 게임 이상 탐지 논문 리뷰 - An Empirical Study of Anomaly Detection in Online Games
AI 프로젝트를 위해 과장님께서 도움이 될만한 논문을 추천해주셨다. 그냥 읽으면 안읽을거 같아서 정리하며 읽어보자! 사람이 정리한 글! Abstract 온라인 게임에 대한 경험적 연구에 대해 기술함
sseozytank.tistory.com
INNE (Isolation-baed anomaly detection using nearest-neighbor ensembles)
E가 딱 앙상블이길래 추가 했을 뿐
https://onlinelibrary.wiley.com/doi/abs/10.1111/coin.12156
이게 논문인데 알 필요는 굳이 ?
- 최근접 이웃 앙상블(nearest neighbour ensemble)을 사용하여 이상치를 탐지
- 데이터 공간을 부분 샘플(subsample)을 통해 여러 영역으로 분할하고, 각 영역에 대해 고립 점수(isolation score)를 계산
- 각 영역은 지역적 분포(local distribution)에 적응하므로, 계산된 고립 점수는 지역 이웃(local neighbourhood)에 상대적인 지역적 척도(local measure)가 되어 전역적 이상치(global anomalies)와 지역적 이상치(local anomalies) 모두를 탐지
참고자료
https://wndofla123.tistory.com/97#google_vignette
[Python/ML] 이상 탐지 (Anomaly Detection)
이상 탐지 (Anomaly Detection) 최근에 관심이 생긴 이상탐지 (Anomaly Detection) 에 대해 알아보자. 이상 탐지의 개념 이상 탐지 (Anormaly Detection) 이란, 예상되거나 기대되는 관찰값, item, event 가 아닌 데이
wndofla123.tistory.com
https://jayhey.github.io/novelty%20detection/2018/01/29/Novelty_detection_KNN/
k-최근접이웃 기반 이상치 탐지(k-NN based Novelty Detection)
이전까지는 밀도 기반 이상치 탐지 기법들에 알아보았다면 이번에는 거리 기반 이상치 탐지 기법 중 가장 기본적은 k-근접이웃 기반 이상치 탐지에 대하여 알아보겠습니다.
jayhey.github.io