DBMS에서 제공하는 내장함수 (Built-in Function)은 두 가지로 분류 할 수 있다
단일행 함수 (Single-Row Function)
다중행 함수 (Multi-Row Function)
- 집계함수 (COUNT, SUM, AVG), 그룹함수(ROLLUP, CUBE), 윈도우함수(RANK, ROW_NUMBER) 등이 해당
문자함수
LOWER (args)
- args: 문자열 값 또는 문자열형
- 입력된 문자열을 모두 소문자로 반환
UPPER (args)
- args: 문자열 값 또는 문자열형
- 입력된 문자열을 모두 대문자로 반환
CHR (args)
- args: ASCII 코드값
- SQL server에서는 CHAR으로 사용
- ASCII 코드값에 대흥하는 문자를 반환
TRIM ([[arg1], [arg2] FROM] arg3])
- arg1: LEADING, TRAILING, BOTH (default : BOTH)
- arg2 : 제거할 특정 문자 혹은 문자열 (default : 공백)
- arg3 : 문자열 값 혹은 문자열형
- 문자열의 양 끝단에서 공백 또는 지정된 문자열을 제거하고 반환
- Trimming : 다듬기
ex) SELECT TRIM(' GOOD ') FROM DUAL;
-> GOOD
ex) SELECT TRIM(LEADING '가' FROM '가나다라') FROM DUAL;
-> 나다라
ex) SELECT TRIM(TRAILING '가' FROM '가나다라') FROM DUAL;
-> 가나다
LTRIM(arg1, [,arg2])
- arg1: 문자열 값 또는 문자열형
- arg2: 제거할 특정 문자 혹은 문자열 (default : 공백)
- SQL server에서는 arg2 인자가 없어 공백만 제거 가능
ex) SELECT LTRIM('가나다라','가') FROM DUAL;
-> 나다라
ex) SELECT LTRIM('가나다라','나') FROM DUAL;
-> 가나다라
RTRIM(arg1, [,arg2])
- arg1: 문자열 값 또는 문자열형
- arg2: 제거할 특정 문자 혹은 문자열 (default : 공백)
- SQL server에서는 arg2 인자가 없어 공백만 제거 가능
ex) SELECT RTRIM('가나다라','라') FROM DUAL;
-> 가나다
ex) SELECT RTRIM('가나다라','나') FROM DUAL;
-> 가나다라
SUBSTR(arg1, arg2 [, arg3])
- arg1: 문자열 값 또는 문자열형
- arg2 : 문자열 추출 시작점 (Index 1부터 시작)
- arg3 : 문자열의 길이 (끝점 x)
- default : 문자열 끝까지 반환
- 입력된 문자열의 부분 문자열을 추출하여 반환
ex) SELECT SUBSTR ('Good Morning', 1, 4) FROM DUAL;
-> Good
LENGTH (args)
- args: 문자열 값 또는 문자열형
- SQLserver에서는 LEN 으로 사용
- 입력된 문자열의 길이를 반환
REPLACE(arg1, arg2 [, arg3])
- arg1 : 문자열 값 또는 문자열형
- arg2 : 변경할 대상 문자열
- arg3 : 변경후 문자열 (default : '' (삭제))
ex) SELLECT REPLACE('Good Morning', 'Morning', 'Afternoon')
-> Good Afternoon
숫자함수
절댓값 : ABS
SELECT ANS(-2.7) FROM DUAL;
-> 2.7
올림 : CEIL (Only 정수)
SELECT CEIL(-2.7) FROM DUAL;
-> -2
반올림 : ROUND
SELECT ROUND(-2.71, 1) FROM DUAL;
-> -3
내림 : FLOOR (Only 정수)
SELECT FLOOR(-2.7) FROM DUAL;
-> -3
버림 : TRUNC
SELECT TRUNC(-2.7) FROM DUAL;
-> -2
SELECT TRUNC(-2.76 ,1) FROM DUAL;
-> -2.7
나머지 : MOD
SELECT MOD(9, 2) FROM DUAL;
-> 1
-1, 0 ,1 변환 : SIGN
- 양수면 1, 0이면 0, 음수면 -1로 반환
SELECT SIGN(2.3) FROM DUAL
-> 1
날짜 함수
SYSDATE
- 오늘의 날짜를 날짜형으로 반환한다
- SQLServer 에서는 GETDATE()를 사용
SELECT SYSDATE AS TODAY FROM DUAL;
EXTRACT (arg1 FROM arg2)
- arg1 : YEAR, MONTH, DAY, HOUR, MINUTE, SECOND
- 날짜로부터 년,월,일을 추출해서 반환
- SQL Server인경우 DATEPART(arg1, arg2)를 사용
SELECT SYSDATE AS TODAY, EXTRACT(MONTH FROM SYSDATE) AS MON,
EXTRACT(DAY FROM SYSDATE) AS DAY
FROM DUAL;
> 2024-03-02 14:28:39:11.000 3 2
변환 함수
형 변환에는명시적 형변환과 암시적 형변환이 존재한다
TO_NUMBER(arg1)
- arg1: 문자열 값 또는 문자열형
- 데이터 타입을 숫자형으로 변환
SELECT TO_NUMBER('1001' ) AS MEMBER_ID FROM DUAL;
TO_CHAR(arg1 [, arg2])
- arg1: 숫자형/날짜형의 값 또는 칼럼
- arg2 : arg1이 날짜형일 경우 사용 (날짜포맷을 나타내는 문자열)
- 데이터 타입을 문자열형으로 변경
SELECT TO_CHAR(SYSDATE, 'YYYYMMDD') AS TODAY FROM DUAL;
> 20240302
TO_DATE (arg1, arg2)
- arg1: 문자열 값 또는 문자열형
- arg2: arg1의 날짜 포멧을 나타내는 문자열
- 데이터 타입을 날짜형으로 변환
SELECT TO_DATE('20240130', 'YYYYMMDD') AS TODAY FROM DUAL;
NULL 관련 함수
NVL(arg1, arg2)
- arg1: 칼럼 또는 표현식
- arg2: 칼럼 또는 표현식(arg1과 같은 데이터 타입을 가져야 한다)
- 첫번째 인자 arg1이 NULL이 아니면 첫 번째 인자를 그대로 반환하고 NULL이면 arg2를 반환
- SQL server g에서는 NVL대신 ISNULL을 사용


NULLIF(arg1, arg2)
- arg1: 칼럼 또는 표현식
- arg2 : 칼럼 또는 표현식(arg1과 같은 데이터 타입을 가져야 한다)
- 입력된 두 인자가 같으면 NULL을 반환 다르면 첫 번째 인자를 반환


COALESCE (arg1 [[.arg2] ...])
- arg1: 칼럼 또는 표현식
- arg2 : 칼럼 또는 표현식(arg1과 같은 데이터 타입을 가져야 한다)
- 입력된 인자를 순서대로 평가하여 NULL이 아닌 첫번째 인자를 반환
그룹 함수
- 기본적으로 GROUP BY 절에 따른 결과에 대해서 그룹 별로 연산을 수행하는 함수 (ex) 집계함수
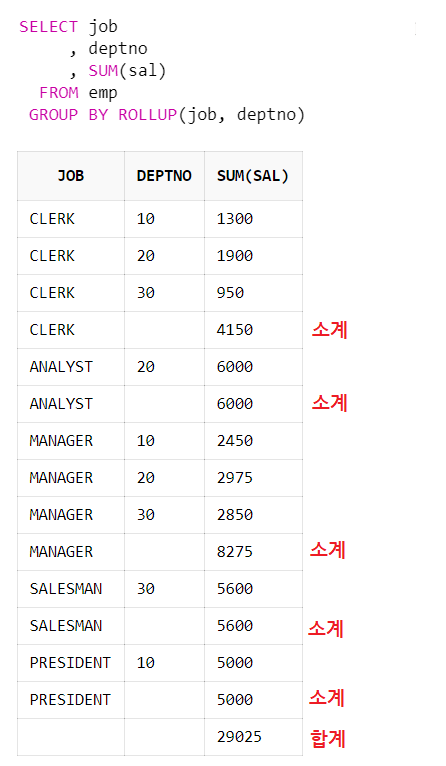
ROLLUP
- GROUP BY 절에 들어가는 ㅋ ㅏㄹ럼을 대상으로 하위 그룹핑을 수행하는 함수
- 주로 소계나 총계를 구할 때 사용
ex)
SELECT CYL, COUNT(*)
FROM MTCARS
GROUP BY ROLLUP(CYL, GEAR)
ORDER BY CYL;
- 실린더 수, 기어 수 별로 그룹핑하여 그룹 별 개수를 구하고, 실린더 수 소계, 총계를 구한다
CUBE
- ROLLUP과 비슷하지만 ROLLUP이 1차원 적인 하위 그룹핑만 수행하지만
- CUBE는 모든 경우로 그룹핑을 수행한다 (인자가 1개인 경우는 ROLLUP과 동일)
- 두개 이상인 경우
- ex) GROUP BY CUBE(날짜, 이름)
- (날짜,이름) => (날짜) => (이름) => (전체)의 순서로 하위 그룹을 묶는다
GROUPING SETS
- GROUPING SETS는 그룹핑할 대상을 지정하는 함수
- ROLLUP과 CUBE는 자동으로 소계, 총계 형태로 그룹핑
- GROUPING SETS를 사용하면 입력된 인자에 대해서만 소계를 구함
GROUPING
- 주로 CASE문과 함께 사용
- 소계에 해당하는 결(1)과 행과 그렇지 않은 행(0)을 0과 1로 구분
- ex)
SELECT CASE GROUPING(CYL)
WHEN 1 THEN '총계' ELSE TO_CHAR(CYL)
END AS CYL,
COUNT(*)
FROM MTCARS
GROUP BY ROLLUP(CYL)
ORDER BY CYL;
TO_CHAR(CYL) : '총계'라는 문자열과 같은 칼럼으로 출력하기 위해 문자열 형으로 변환
GROUP BY ROLLUP(CYL) : CYL에 따라 GROUP BY 하며 마지막에 총계를 나타내는 행이 추가된다
윈도우 함수
윈도우 함수는 행과 행 간의 관계를 나타내는 연산을 쉽게 하기 위한 함수
- GROUP BY 연산은 각 행을 대상으로 연산을 수행하고 새로운 구성을 만듬
- WINDOW 연산은 기존 구성을 유지한 상태로 해당 행에 대해서 새로운 값을 추가./변경
순위 함수
RANK()
- 동일 순위는 같은 순위 값을 가짐
- 순위 값은 앞 순위까지의 누적 개수 +1 이된다
- ex) 1,2,2,4,4,4,7
DENSE_RANK()
- 동일 순위는 같은 순위 값을 가짐
- 순위 값은 단순 하게 앞 순위 +1
- ex) 1,2,2,3,3,3,4
ROW_NUMBER()
- 동일 순위라도 각각의 행이 고유의 순위값을 가짐
- ex)1,2,3,4,5,6,7
ex)
SELECT MPG, COUNT(*), RANK() OVER(ORDER BY COUNT(*) DESC) AS RANK
FROM MTCARS
GROUP BY MPG;
-> GROUP BY -SELECT 순으로 되므로 COUNT(*)은 MPG별 개수 이다
-. 해당 그룹에 속한 레코드 수가 많은 것 부터 순서대로 순위가 매겨지고
- 동일 순위는 같은 값을 가지고, 이전 순위까지의 누적 개수 +1의 순위를 가진다
집계 함수
OVER 절을 사용해서 파티션 별로 집계하거나 누적 집계를 구한다
COUNT, SUM, AVG, MIN, MAX
ex)
SELECT NAME, CYL,MPG
MAX(MPG) OVER(PARTITION BY CYL) AS PART_CYL_CNT
FROM MTCARS
WHERE CYL <= 6;
행 순서 함수
- SQL SERVER에서는 행 순서함수를 지원하지 않는다
FIRST_VALUE(arg) LAST_VALUE(arg)
- 파티션 별로 그룹핑하여 각각 가장 첫번째 값을 반환 한다
FIRST_VALUE(arg) LAST_VALUE(arg)
- 파티션 별로 그룹핑하여 각각 가장 마지막 값을 반환 한다
LAG(arg, n)
- 입력된 인자 만큼의 이전 행의 값을 반환 (결과 기준)
LEAD(arg, n)
- 입력된 인자 만큼의 이후 행의 값을 반환 (결과 기준)
ex)
SELECT NAME, CYL, MPG
LAG(MPG, 2) OVER (ORDER BY MPG) AS MPG_2
FROM MTCARS
WHERE CYL <= 6;
CYL이 6 이하인 레코드들에 대해 MPG 값을 오름차순으로 정렬하고 원래 MPG값과 2행 앞의 MPG 값을 조회 한다
비율 함수
DENSE_RANK()
- 동일 순위는 같은 순위 값을 가짐
DENSE_RANK()
- 동일 순위는 같은 순위 값을 가짐
DENSE_RANK()
- 동일 순위는 같은 순위 값을 가짐
DENSE_RANK()
- 동일 순위는 같은 순위 값을 가짐
'IT Study > SQL' 카테고리의 다른 글
| [SQLD] 집합연산자 (0) | 2026.03.04 |
|---|---|
| [SQLD] 서브 쿼리(Subquery) 와 뷰(VIEW) (0) | 2026.03.03 |
| [SQLD] JOIN 함수 관련 총정리 (0) | 2026.02.24 |
| [SQLD] SQL 기본 및 활용 (관리 구문) (0) | 2025.11.11 |
| [SQLD] 데이터베이스 이상현상 및 정규화/반정규화 (0) | 2025.11.03 |
