![[Pytorch] Pytorch 압축정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FNE9AC%2Fbtsizefbj0w%2Fi2QqAJCd5mWYQNoJtqTbG1%2Fimg.png)
소개
Pytorch vs TensorFlow
딥러닝을 할때 좀 더 편리하게 해주는 일종의 "FrameWork"라 생각하면 된다
지금 선두하고 있는 Framework는 두가지 이다
Pytorch : Facebook에서 만듬
TensorFlow : Google에서 만듬
이 둘의 차이는 다음과 같다

keras 와 TensorFlow는 현재 합쳐져 있다
그래서 TensorFlow 와 Pytorch의 차이를 보면
가장 큰 차이점은 Computational graphs Used에 있는데
결국 학습을 위해서는 미분을 하여서 Backpropagation을 진행해야 하고 이를 위해서는 현재있는 데이터를 그래프로 표현을 해야한다
이때 TensorFlow 는 Static graph로 그래프를 Static하게 그려서 실행시점에서 Backpropagation을 진행하고 (Define and run)
-> 그래프를 먼저 정의하여서 실행시점에 데이터를 Feed시켜줌 (데이터를 넣는다)
이러한 성격 때문에 Multi gpu, Production, Cloud 연결 등에 강점을 가진다
Pytorch의 경우는 Dynamic하게 graph를 그려서 실행시점에서 graph가 그려진다는 차이가 있다 (Define by run)
-> 실행을 하면서 그래프를 생성하는 방식
주로 논문, 구현등에 사용한다
Pytorch에 대해서 더 정리를 해보면

Define by Run의 장점의 가장 큰 장점은 즉시 확인이 가능하다는 것이다 (Pythonic code) -> compile이 필요없음
GPU 지원과 , API 나 Community를 가지고 있다
Keyword
근본적으로 다음 세가지가 핵심 키워드 이다
1. Numpy (Numpy 구조를 가지는 Tensor 객체로 array를 표현 한다)
2. AutoGrad (자동미분)
3. Function (다양한 딥러닝 함수)
Tensor 생성과 GPU (Numpy와 유사)
Numpy + AutoGrad
-> 사실 Numpy만 잘 알아도 반 이상은 간다
Numpy에서 list 는 Ndarray로 핸들링을 하는데
이를 Pytorch에서 Tensor 라는 객체로 사용한다
그래서 Ndarray = Tensor 라고 생각 할 수 있다
import numpy as np
import torch
np_array = np.arange(10).reshape(2,5)
print(np_array)
print("n_dim", np_array.ndim, "shape", np_array.shape)
t_array = torch.FloatTensor(np_array)
print(t_array)
print("t_dim", t_array.ndim, "shape", t_array.shape)
Tensor 생성하는 방법
# numpy to Tensor
np_array = np.arange(10).reshape(2,5)
tensor1 = torch.FloatTensor(np_array)
tensor2 = torch.from_numpy(np_array)
tensor3 = torch.Tensor(np_array)
#list to Tensor
lst = [[0,1,2,3,4],[5,6,7,8,9]]
tensor4 = torch.FloatTensor(lst)
tensor5 = torch.Tensor(lst)
이렇게 다양하게 생성할 수 있다


생각보다 ones_likerk aksgdl tkdydgksek
이렇게 보면 numpy랑 다를게 없어 보이지만 Numpy와의 가장 큰 차이는 GPU를 쓸 수 있냐 없냐 이다
Pytorch의 Tensor는 GPU에 올려서 사용가능하다
x_data = torch.tensor([[0,1,2],[3,4,5],[6,7,8]])
#check the device
print(x_data.device) # >> device(type ='cpu')
#Try attach for GPU
if torch.cuda.is_available():
x_data_cuda = x_data.to('cuda')
print(x_data_cuda.device) # >> device(type='cuda', index=0)
Tensor Handling
- View : reshape과 동일하게 tensor의 shape을 변환
- Squeeze : 차원의 개수가 1인 차원을 삭제 (압축)
- Unsqueeze : 차원의 개수가 1인 차원을 추가 (확장)
1. View (verse reshape)
-> view 와 reshape의 차이는 있긴 하지만 reshape 쓸 부분에 view를 쓰기만 하면 되긴 하다
x_data = torch.tensor([[0,1],[2,3],[4,5]])
print(x_data.view(2,3))
print(x_data.reshape(2,3))
결과는 동일한데 어떤 차이가 있을까?
x_data = torch.zeros(3,2)
y = x_data.view(2,3)
y.fill_(1)
print(x_data)
print(y)
x_data = torch.zeros(3,2)
y = x_data.T.reshape(6)
y.fill_(1)
print(x_data)
print(y)다음 코드에서는 차이를 보인다

view의 경우 y가 x를 Copy 한 것이 아닌 동일한 메모리에 표현하는 형태만 달라진 것이다
reshape의 경우 copy를 한 것으로 볼 수 있는데 매번 copy를 하는 것이 아닌 일종의 "조건부 copy"이다
메모리는 이차원이던 3차원이던 다음과 같이 0,1,0,1,1,1,0 이런 식으로 값들을 저장을 하는데
이것을 view는 보장을 해주는 것이고 reshape 같은 경우는 위의 구조가 깨지는 순간 copy를 하는 것이다
결론 : 그냥 view 쓰자
2. Squeeze & unsqueeze
-> 차원을 바꿀 때 사용한다

unsqueeze(index) : index의 부분에 1을 붙여 준다
data = torch.rand(size=(2,1,2))
#(2,1,2) -> (2,2)
print(data, data.shape,"\n")
print(data.squeeze(), data.squeeze().shape,"\n")
#(2,2)
data = data.squeeze()
#(2,2) -> (1,2,2)
print(data.unsqueeze(0), data.unsqueeze(0).shape,"\n")
#(2,2) -> (2,1,2)
print(data.unsqueeze(1), data.unsqueeze(1).shape,"\n")
#(2,2) -> (2,2,1)
print(data.unsqueeze(2), data.unsqueeze(2).shape,"\n")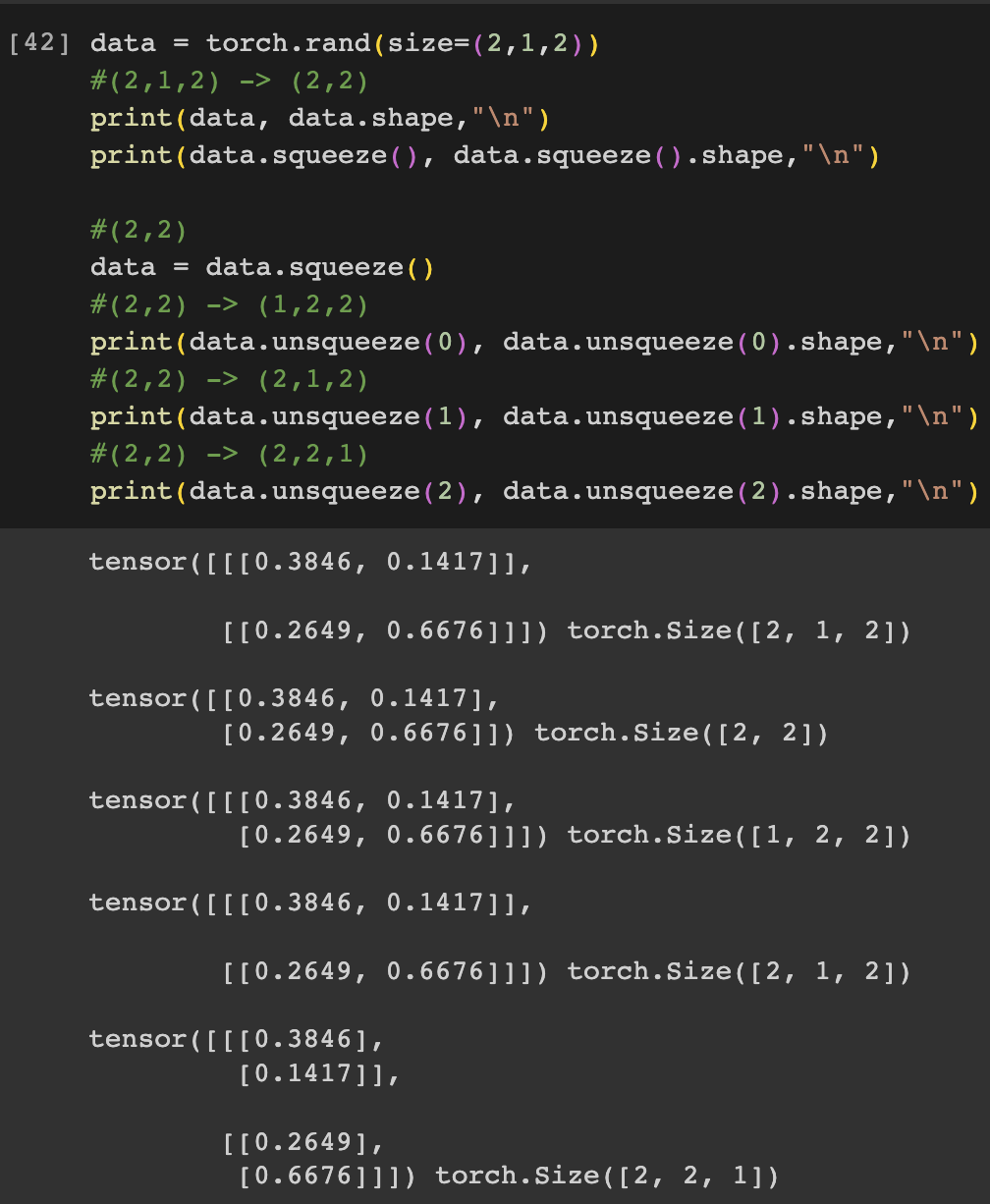
행렬의 곱셈 (mm, matmul 사용)
행렬의 곱셈에 있어서 dot product 과 matmul을 구분해서 사용한다
(dot은 스칼라나 벡터에서 사용을 한다)
스칼라 & 벡터 연산 : dot
행렬 : matmul mm
그러므로 mm혹은 matmul을 사용하자
a = torch.rand(5,2)
b = torch.rand(2,5)
print(a)
print(b)
print(a.mm(b))
print(a.matmul(b))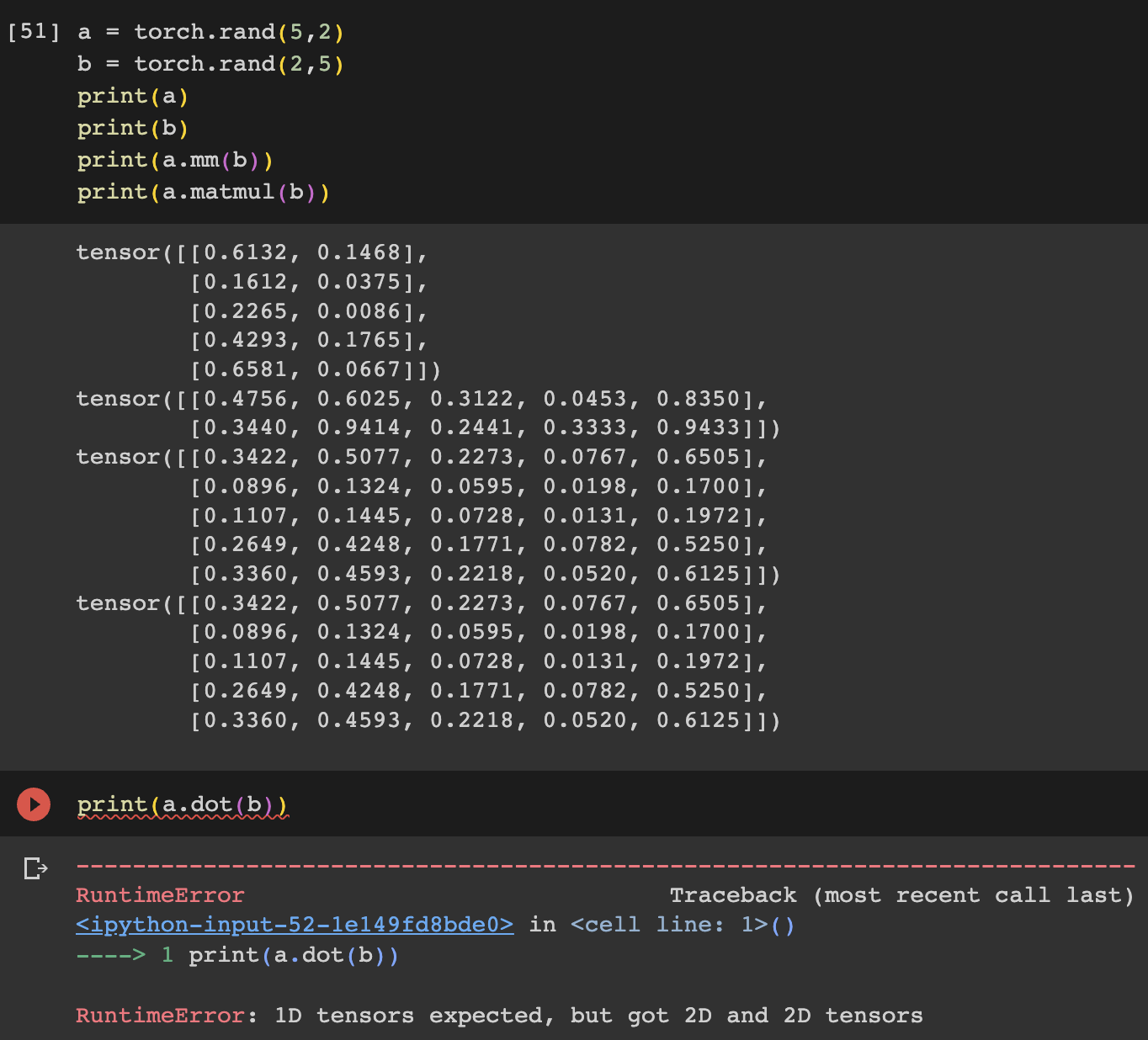
추가로
matmul은 broadcasting을 조심해야한다
이것 때문에 mm을 선호하는 경우도 있다
torch.nn.functional
아래의 import를 해주면 다양한 수식변환을 쉽게 가져올 수 있다
import torch.nn.functional as F이걸 임포트 해주면 아래와 같은 것들을 쉽게 해줄 수 있다
import torch.nn.functional as F
tensor = torch.FloatTensor([0.5,0.6,0.7])
s_tensor = F.softmax(tensor, dim = 0)
print(s_tensor)
y = torch.randint(5,(10,5))
y_label = y.argmax(dim=1) #임의의 label을 만듬
torch.nn.functional.one_hot(y_label)
AutoGrad
옵션을 통해 미분을 해줄 대상을 지정해줄 수 있다 (Weight 등)
w = torch.tensor(2.0, requires_grad=True)예시 1

w = torch.tensor(2.0, requires_grad=True)
y = w**2
z = 10*y + 50
z.backward()
w.grad와 같이 backpropagation을 이용하여서 미분값을 뽑아낼 수 있다
예시 2

#편미분
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.]) #a에 관한 미분, b에 관한 미분
Q.backward(gradient=external_grad)
print(a.grad, b.grad)
'AI Track > AI Basic' 카테고리의 다른 글
| [총정리] Pytorch로 AI 모델링을 하는데 필요한 모든 것 (0) | 2024.08.02 |
|---|---|
| [AI] 2023 AI 트렌드 살펴보기 (CV, NLP) (1) | 2023.07.06 |
| [Pytorch Basic] 모델을 가져와서 Fine Tuning하기 (0) | 2022.10.03 |
| [Pytorch Basic] Pytorch DataSets and DataLoaders (0) | 2022.10.03 |
| [Basic Pytorch]AutoGrad & Optimizer (0) | 2022.10.02 |