※제가 이해하기 위한 의역이 들어간 점 주의바랍니다

Abstract
Googlenet의 가장 큰 특징은 네트워크 내부의 컴퓨팅 자원의 향상된 활용도 이다
(이유) 계산량을 일정하게 유지하면서 네트워크의 깊이와 폭을 늘릴 수 있도록 해줌
(based on the Hebbian principle and the intuition of multi-scale processing)
Google팀에서 만들 었고 22개의 layer를 가진다고 한다
Introduction
One encouraging news is that most of this progress is not just the result of more powerful hardware, larger datasets and bigger models, but mainly a consequence of new ideas, algorithms and improved network architectures
3년동안 image recognition, object detection이 발전해왓는데 이건 강력한 하드웨어나 많은 데이터셋, 큰 모델로 인하긴 했지만 new idea 와 algorithms, 개선된 네트워크 구조 덕분에 발전한 것 이다
약간 우리는 개선된 네트워크 구조 가져왔어~ 데이터 늘리고 모델 크게 해봤자야 이런 느낌으로 말한거 같다
Our GoogLeNet submission to ILSVRC 2014 actually uses 12× fewer parameters than the winning architecture of Krizhevsky et al [9] from two years ago, while being significantly more accurate.
우리 parameter 수도 12배 적은데 더 정확하다?? 엄청나지~??
but from the synergy of deep architectures and classical computer vision, like the R-CNN algorithm by Girshick~
우리는 모델을 크게 가져간게 아니라 Girshick 등의 R-CNN 알고리즘과 같은 심층 아키텍처와 고전적인 컴퓨터 비전의 시너지 효과에 주목을 하였다.
위에 예상했던 대로 주장하는거 같다.
Another notable factor is that with the ongoing traction of mobile and embedded computing, the efficiency of our algorithms – especially their power and memory use – gains importance.
It is noteworthy that the considerations leading to the design of the deep architecture presented in this paper included this factor rather than having a sheer fixation on accuracy numbers
다른 자랑하고 싶은 거는 우리는 임베디드 시스템이나 모바일이 유행이 되면서 단순히 정확도의 숫자에 집학을 하는 것이 아니라 power하고 memory에 집중을 하였다
(1.5 billion multiply-adds at inference time을 유지 하였으며 이래서 대규모 데이터셋에도 사용할 수 있다)
모바일에서도 돌아갈 수 있도록 고려했다는 점에서 이 논문에 주목을 하였다
Codename::Inception

미국에는 “we need to go deeper” 라는 밈이 있다고 하고 (찾아보니깐 진짜 Inception 영화 대사에 있다고 함)여기에서 아이디어를 얻어 인셉션이라 했단다
“Deep" 이라는 의미를 두가지로 해석했다고 한다
1. a new level of organization in the form of the “Inception module”
(Inception module 이라는 형태의 새로운 level의 조직)
2. more direct sense of increased network depth
(네트워크의 깊이를 증가)
일단 굉장히 유머감각이 떨러지는 거 같고 무엇보다 왜 네트워크 깊이가 증가 했다는 말을 했는지 이해를 못했다

Related Work
<기존의 CNN 모델들>
LeNet-5를 기점으로 약간 국룰적으로 Conv layer 쌓고 (가끔 Contrast normalization 이나 max-pooling 추가하고) 그 뒤에 다가 1개이상의 FC(fully connected layer)를 쌓음
=> ImageNet 이나 CIFAT, MNIST에 특화되어있는 방법임
그러다가 요즘 추세가 데이터 셋이 커지만 layer를 더 쌓고 size를 늘리고 overfitting 방지하려고 Dropout 추가한다
나 또한 프로젝트를 진행할 때 이 방식을 선택하였다
Max pooling layer 가 정확한 공간 정보의 손실을 초래하자나 근데 성능이 생각보다 괜찮음
(Human pose estmation이나 Object detection에서)
Serre et al. [15] use a series of fixed Gabor filters of different sizes in order to handle multiple scales, similarly to the Inception model.
[참고]Gabor Filter
외각선을 검출하는 기능를 하는 필터 (사람의 시각체계와 비슷하다는 이유로 널리 사용

σ (sigma) : Kernel 의 너비 ( Standard deviation of the gaussian envelope )
θ (theta) : Kernel 의 방향성 ( 추출하는 Edge의 방향을 결정, Orientation of the normal to the parallel stripes of a Gabor function)
λ (lambd) : 사인파 인자의 파장(wavelength of the sinusoidal factor)
γ (gamma) : 공간종횡비(spatial aspect ratio)
ψ (psi) : 위상오프셋
[출처] [OpenCV]Gabor Filter|작성자 부루맨
However, contrary to the fixed 2-layer deep model of [15], all filters in the Inception model are learned. Furthermore, Inception layers are repeated many times, leading to a 22-layer deep model in the case of the GoogLeNet model.
위에 애는 고정된 2-layer의 deep model을 사용하는데 Googlenet은 학습을 한다고하고 이 것은 22개의 layer로 구성된다고 한다
Network-in-Network is an approach proposed by Lin et al. [12] in order to increase the representational power of neural networks. When applied to convolutional layers, the method could be viewed as additional 1×1 convolutional layers followed typically by the rectified linear activation
Network in Network(이거 논문임)
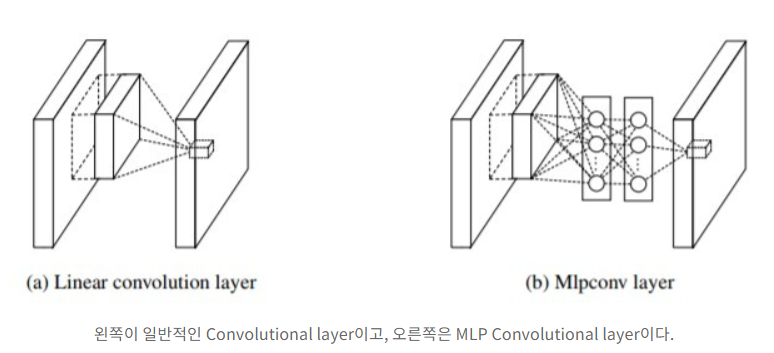
데이터 분포가 비선형적일때 일반적인 CNN구조로는 특징을 추출하기 어려워서 중간에 MLP를 낑겨 넣음

*CCCP (Cascaded Cross Channel Pooling)
channel을 직렬로 묶어 픽셀 별로 pooling을 수행하는 것
(feature map 크기는 그대로, channel 수만 줄어들음) => 차원 축소
밑에 1x1 convolution과 매우매우 유사(논문에서 유사하대요...)

However, in our setting, 1 × 1 convolutions have dual purpose: most critically, they are used mainly as dimension reduction modules to remove computational bottlenecks, that would otherwise limit the size of our networks. This allows for not just increasing the depth, but also the width of our networks without significant performance penalty.
Googlenet에서 1 x 1 Convolution 사용한 이유
1. (주요) 차원 축소 (to remove computational bottlenecks)
2. 네트워크 사이즈 제한 ( increasing the depth, width of our networks without significant performance penalty)
2 번째 이유에서 위에서 이해가 안되었던 더 깊이 라는 의미를 알 수 있다 : 네트워크 사이즈 제한을 두어 더 깊게 할 수 있는 가능성(?)을 주었다 라고 이해하면 될 듯 하다
This is as an easy and safe way of training higher quality models, especially given the availability of a large amount of labeled training data. However this simple solution comes with two major drawbacks.
쉽고 안전하고 높은 퀄리티의 모델이지만 두가지 단점이 있다고 한다
*단점*
1. size가 커진다 -> parameter증가한다 -> overfitting 일어난다
ImageNet은 1000 class로 구분을 해야하는데 이러면 bottleneck이 일어남
2. size가 커진다 -> 컴퓨터 자원을 많이 사용한다
The fundamental way of solving both issues would be by ultimately moving from fully connected to sparsely connected architectures, even inside the convolutions.
두 문제를 해결하는 근본적인 방법은 fully connected에서 sparsely connected로, 아니면 컨볼루션 내부로 이동하는 것입니다. -> 하지만 비효율적이라 하네요
(On the downside, todays computing infrastructures are very inefficient when it comes to numerical calculation on non-uniform sparse data structures.)
The Inception architecture started out as a case study of the first author for assessing the hypothetical output of a sophisticated network topology construction algorithm that tries to approximate a sparse structure implied by [2] for vision networks and covering the hypothesized outcome by dense, readily available components.
(...)
After further tuning of learning rate, hyperparameters and improved training methodology, we established that the resulting Inception architecture was especially useful in the context of localization and object detection as the base network
정교한 network topology construction algorithm을 만들려고 노력을 하였고 이후 learning rate나 hyperparameter를 조정하면서 괜찮은 결과를 얻었다고 합니다
Architectural Details
그래서 어떻게 했는데!!!
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components
(...)
All we need is to find the optimal local construction and to repeat it spatially
CNN에서 각 요소를 최적의 local sparse structure을 근사화 하고 dense components로 커버할 수 있는(바꿀수 있는) 방법을 찾아봤다 -> 이걸 찾으면 이걸 계속 반복하면 되지 않냐!!!
Arora et al. [2] suggests a layer-by layer construction in which one should analyze the correlation statistics of the last layer and cluster them into groups of units with high correlation. These clusters form the units of the next layer and are connected to the units in the previous layer. We assume that each unit from the earlier layer corresponds to some region of the input image and these units are grouped into filter banks.
Arora et al는 말하길 가장 마지막 layer의 상관성 통계를 분석하여서
상관 관계가 높은 그룹단위로 묶어나가는 것을 제안했다.(이렇게 생성된 묶음은 다음 layer의 단위를 만들고 이전 layer의 단위에 연결된다)
Google 생각 :
이전 계층의 각 단위가 이미지의 일부에 해당하는거 아닐까? (일부를 요약해주는 느낌) -> 이거를 filter bank로 묶어보자 !!
In the lower layers (the ones close to the input) correlated units would concentrate in local regions. This means, we would end up with a lot of clusters concentrated in a single region and they can be covered by a layer of 1×1 convolutions in the next layer
input이랑 가장 가까운 layer는 이미지의 특정 부분에 Correlated unit이 집중되어 있을 것이다.
집중되어 있으니깐 (많은 cluster들이 똑같은 영역에 몰려있으니)이는 1x1 Conv로 충분히 커버된다
However, one can also expect that there will be a smaller number of more spatially spread out clusters that can be covered by convolutions over larger patches, and there will be a decreasing number of patches over larger and larger regions.
이쯤 드는 생각: 밑에 같은 경우에는 1x1 Conv로 커버를 못하지 않나??
<patch-alignment issues>-> 구글이 이렇게 부름

In order to avoid patchalignment issues, current incarnations of the Inception architecture are restricted to filter sizes 1×1, 3×3 and 5×5, however this decision was based more on convenience rather than necessity
그래서 Inception에서는 1x1, 3x3, 5x5를 같이 써서 이 문제를 해결하고자 함.
(필요성보다는 편의성에 초점)
-> 말은 이쁘게 했지만 그냥 1x1, 3x3, 5x5 깔아서 feature 뽑으려 했다는 것 같다
Additionally, since pooling operations have been essential for the success in current state of the art convolutional networks, it suggests that adding an alternative parallel pooling path in each such stage should have additional beneficial effect, too
여기저기에서 Pooling이 좋다고 하니깐 추가했다고 합니다
as features of higher abstraction are captured by higher layers, their spatial concentration is expected to decrease suggesting that the ratio of 3×3 and 5×5 convolutions should increase as we move to higher layers.
One big problem with the above modules, at least in this na¨ıve form, is that even a modest number of 5×5 convolutions can be prohibitively expensive on top of a convolutional layer with a large number of filters
layer가 깊어질 수록 높은 차원의 추상적인 특징이 잡히기 때문에 3x3, 5x5를 점점 늘려갔다(그래서 모양이 뚱뚱함)
이렇기 때문에 깊어질 수록 연산량이 많아지는 문제가 발생해 버린다
<해결 방안> -> 1x1 Conv
That is, 1×1 convolutions are used to compute reductions before the expensive 3×3 and 5×5 convolutions. Besides being used as reductions, they also include the use of rectified linear activation which makes them dual-purpose.
3x3 Conv, 5x5 Conv에 넣기 전에 1x1 Conv돌려서 차원을 축소시켰다. 심지어 1x1 Conv연산 이후에 Relu를 추가해서 비선형적 특징 까지 얻을 수 있음
For technical reasons (memory efficiency during training), it seemed beneficial to start using Inception modules only at higher layers while keeping the lower layers in traditional convolutional fashion.
그럼 Googlenet은 Inception 방식으로만 구성하냐?? -> NO!!! (기술적 요인으로 인해)
앞부분의 layer는 전통적인 CNN 구조를 가지고 뒷 부분에 Inception 구조를 사용하는 것이 좋다고 한다
One of the main beneficial aspects of this architecture is that it allows for increasing the number of units at each stage significantly without an uncontrolled blow-up in computational complexity.
(...)
Another practically useful aspect of this design is that it aligns with the intuition that visual information should be processed at various scales and then aggregated so that the next stage can abstract features from different scales simultaneously.
기술적 요인(두개를 같이 사용하는)
1. 과도한 연산없이 유닛의 숫자를 늘릴 수가 있다 (앞부분은 tradition하게 늘리고 뒤에서는 1x1로 줄이고)
2. 다양한 scale로 처리되고 (1,3,5) 다음 layer는 동시의 여러개의 scale에서 특징을 추출할 수 있어서 좋다
GooLeNet
그래서 어떤 구조인데!!!


Here, the most successful particular instance (named GoogLeNet) is described in Table 1 for demonstrational purposes.
(...)
The size of the receptive field in our network is 224×224 taking RGB color channels with mean subtraction. “#3×3 reduce” and “#5×5 reduce” stands for the number of 1×1 filters in the reduction layer used before the 3×3 and 5×5 convolutions. One can see the number of 1×1 filters in the projection layer after the built-in max-pooling in the pool proj column. All these reduction/projection layers use rectified linear activation as well.
(...)
The use of average pooling before the classifier is based on [12], although our implementation differs in that we use an extra linear layer.
모든 layer는 activation function으로 Relu를 사용한다
Input Image
224 x 224x3(RGB)
Inception Module
9번 진행 : 4번째와 7번째 Module 은 Auxiliary Classifier를 시행
Final layer(Fully Connected Layer)
Global Average Pooling으로 Flatten을 시켜준 다음 1000개의 뉴런과 Fully Connected 한다음 Softmax 적용


추가 설명
GoogLeNet을 4개의 part로 나눠보자
Part 1. 입력이미지와 가장 낮은 레이어

traditional한 CNN모델을 사용
(input -> conv -> pooling -> normalization)
(S),(V)의 의미가 뭔지는 모르겠음
Part 2. Inception module

1x1 , 3x3, 5x5 가 병렬 적으로 연결이 되어 있음
3x3, 5x5 에 들어가기 전에 1x1 Conv를 적용
Part 3. Auxiliary Classifier

Given the relatively large depth of the network, the ability to propagate gradients back through all the layers in an effective manner was a concern.
(...)
By adding auxiliary classifiers connected to these intermediate layers, we would expect to encourage discrimination in the lower stages in the classifier, increase the gradient signal that gets propagated back, and provide additional regularization. These classifiers take the form of smaller convolutional networks put on top of the output of the Inception (4a) and (4d) modules. During training, their loss gets added to the total loss of the network with a discount weight (the losses of the auxiliary classifiers were weighted by 0.3). At inference time, these auxiliary networks are discarded.
Auxiliary Classifier : Vanishing gradient 문제를 해결하기 위해 도입(모델이 깊어지므로)
즉, 중간 layer에 Aux classifier를 추가하여 중간에 결과를 출력해 추가적인 역전파를 일으켜 gradient를 전달 + 정규화 효과
(이건 영향력이 크면 안되니깐 loss에 0.3을 곱하고 평가를 할때는 discard(없앴다) )
얕
왜 중간 layer에 추가를 했냐면 이 부분에서 만들어지는 feature가 매우 차별적이여서
(얕은 신경망의 강한 성능) -> google이 그렇대요..
Part 4. Global Average Pooling

The use of average pooling before the classifier is based on [12], although our implementation differs in that we use an extra linear layer. This enables adapting and fine-tuning our networks for other label sets easily, but it is mostly convenience and we do not expect it to have a major effect. It was found that a move from fully connected layers to average pooling improved the top-1 accuracy by about 0.6%, however the use of dropout remained essential even after removing the fully connected layers.
Global Average Pooling(GAP)을 사용하는 이유 : Softmax를 사용하고 싶어서 + Parameter 감소+ 쉬운 Fine Tuning
밑에 그림과 같이 평균을 때려서 1차원 벡터로 만들기 때문에 가중치가 하나도 필요하지 않음

이걸 쓴다고 해도 Dropout은 써야한다고 하네요
핵심
1x1 Convolution(Sparse구조를 Dense로 근사화)
Inception Module(1x1, 3x3, 5x5 병렬연결)
Auxiliary Classifier(Gradient Vanishing문제 해결)
Global Average Pooling
참고
[논문] GoogleNet - Inception 리뷰 : Going deeper with convolutions
논문 링크 : https://arxiv.org/pdf/1409.4842.pdf Abstract 본 논문은 ImageNet Large-Scale Visual Recognition Challenge 2014(ILSVRC14)에서 classification 및 detection를 위한 최점단 기술인 codename In..
leedakyeong.tistory.com
[CNN] GoogLeNet
소개 GoogLeNet은 2014년도 ILSVRC(ImageNet Large Sclae Visual Recognition Challenge)에서 우승한 CNN 네크워크입니다. 정확하게 보면 GoogLeNet은, Inception이라는 개념의 네트워크들 중 하나입니다. 따..
hnsuk.tistory.com
GoogLeNet (Going deeper with convolutions) 논문 리뷰
논문 제목 : Going deeper with convolutions 이번에는 ILSVRC 2014에서 VGGNet을 제치고 1등을 차지한 GoogLeNet을 다뤄보려 한다. 연구팀 대부분이 Google 직원이어서 아마 이름을 GoogLeNet으로 하지 않았나 싶..
phil-baek.tistory.com



